
Tatsunori Hashimoto
@tatsu_hashimoto
Followers
6,085
Following
203
Media
31
Statuses
161
Assistant Prof at Stanford CS, member of @stanfordnlp and statsml groups; Formerly at Microsoft / postdoc at Stanford CS / Stats.
Stanford
Joined April 2019
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
D-Day
• 467911 Tweets
SpaceX
• 375684 Tweets
Normandy
• 322302 Tweets
CISF
• 310614 Tweets
Gomez
• 230802 Tweets
England
• 160384 Tweets
Starship
• 143031 Tweets
Hunger Games
• 105677 Tweets
Steve Bannon
• 96562 Tweets
WWII
• 92712 Tweets
Jill
• 91045 Tweets
Haymitch
• 80360 Tweets
कुलविंदर कौर
• 79626 Tweets
Lego
• 78074 Tweets
$GME
• 66326 Tweets
Lakers
• 56729 Tweets
Suzanne Collins
• 44742 Tweets
Hurley
• 41409 Tweets
Maddison
• 30653 Tweets
JXW THIS MAN PROLOGUE FILM
• 29754 Tweets
Dunk
• 29677 Tweets
Grealish
• 28058 Tweets
Southgate
• 27518 Tweets
Maguire
• 25985 Tweets
इंदिरा गांधी
• 25650 Tweets
Indira Gandhi
• 20911 Tweets
Stones
• 20834 Tweets
Deco
• 20400 Tweets
Pharrell
• 20170 Tweets
Branthwaite
• 20130 Tweets
UConn
• 20062 Tweets
#ComeToBeşiktaşHummels
• 19026 Tweets
#PakvsUSA
• 18801 Tweets
Dr Pepper
• 18357 Tweets
هلال شهر
• 11911 Tweets




















Pinned Tweet

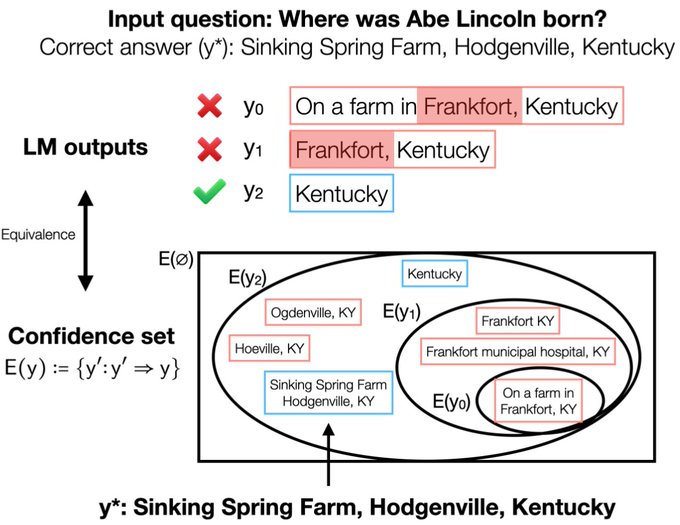
Language model hallucinations are a big problem. Can we build LMs w/ factuality & correctness guarantees?
Conformal factuality is a simple, practical modification to any LM that uses conformal prediction to give exact high-prob. correctness guarantees

11
64
374
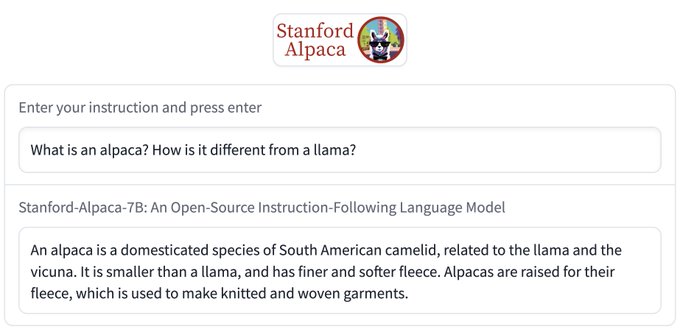
Instruction-following models are now ubiquitous, but API-only access limits research.
Today, we’re releasing info on Alpaca (solely for research use), a small but capable 7B model based on LLaMA that often behaves like OpenAI’s text-davinci-003.
Demo:
43
340
1K
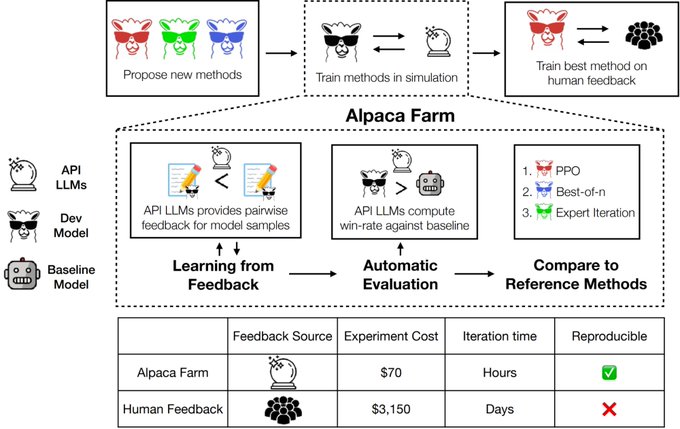
We are releasing AlpacaFarm, a simulator enabling everyone to run and study the full RLHF pipeline at a fraction of the time (<24h) and cost (<$200) w/ LLM-simulated annotators. Starting w/ Alpaca, we show RLHF gives big 10+% winrate gains vs davinci003 ()
7
134
648
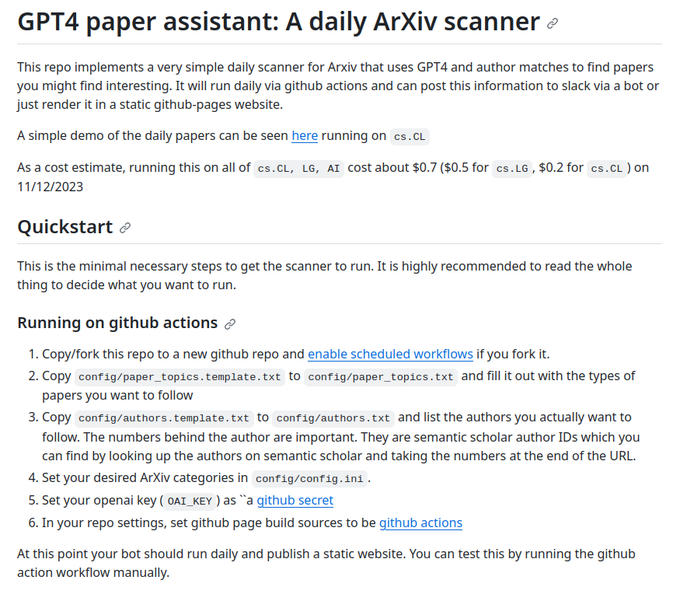
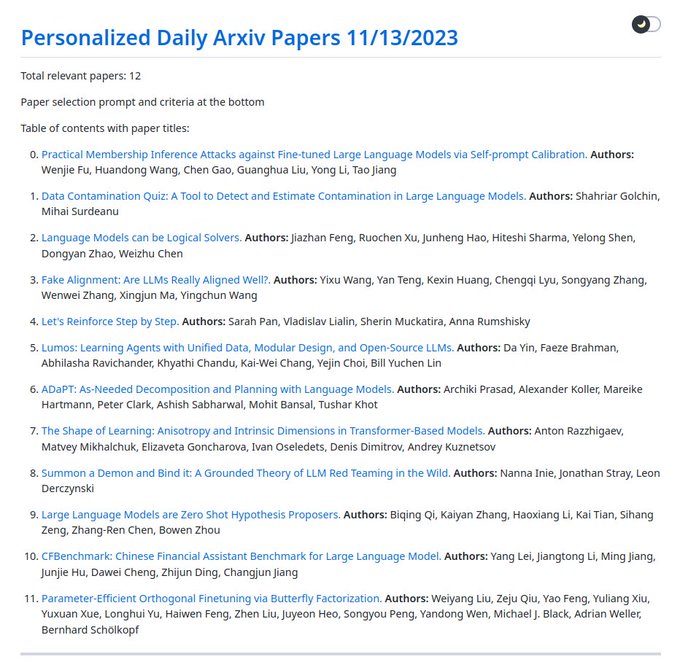
I've been using a GPT4 paper assistant that reads the daily ArXiv feed and makes personalized recommendations in Slack. It's worked pretty well for me (today's paper demo ). If this sounds helpful, you can set up your own bot here .
8
107
613
I'm excited to share that I'll be joining
@Stanford
CS as an Assistant Professor starting Sept 2020 and spending the next year at Semantic Machines.
I'm incredibly grateful for the support I received from friends and colleagues and excited to continue my work at Stanford!
29
15
452
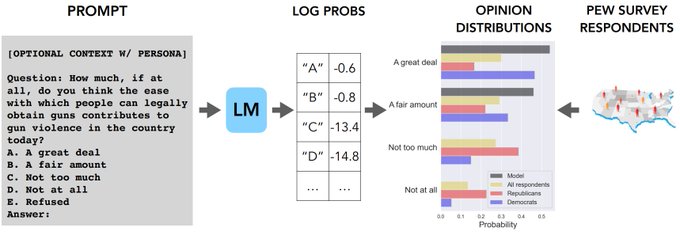
We know that language models (LMs) reflect opinions - from internet pre-training, to developers and crowdworkers, and even user feedback. But whose opinions actually appear in the outputs? We make LMs answer public opinion polls to find out:
4
103
422
How can we trust LM evals when LMs might be pretraining on the test set? We show you can prove suspected test set contamination on black-box models with false positive rate guarantees. An audit of 5 open LMs shows little evidence of strong contamination.

6
54
282
Congrats to
@YonatanOren_
,
@nicole__meister
,
@niladrichat
,
@faisalladhak
on getting a best paper honorable mention for their work on provably detecting test set contamination for LLMs! If you’re interested in contamination, or fun statistical tests, their talk is Thu 4-4:15pm!

3
29
234
Interested in differential privacy (DP) or private NLP?
Our preprint has something for both interests:
We found that privacy-preserving NLP can be painless (code below), and DP-SGD works surprisingly well on extremely large models.
(contd)

2
31
177
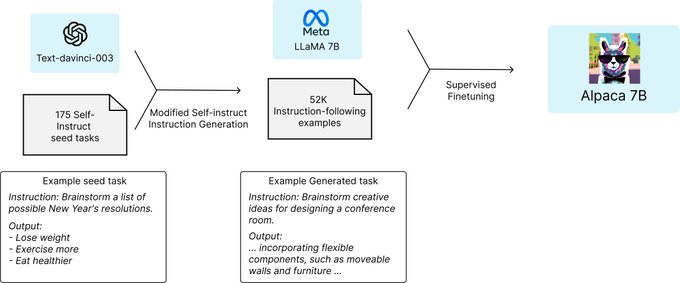
Alpaca is an instruction-tuned version of LLaMA 7B, where our 52k demonstrations are based on the self-instruct method of Wang et al w/ text-davinci-003.
Combining small tuning data and model allows us to train Alpaca quickly (3hrs on 8xA100).
Data:
7
14
95
We release information needed to replicate Alpaca, and we await Meta’s guidance on releasing its weights. We hope releasing Alpaca will let us better understand model failures and facilitate academic research with a strong instruction-following model.

6
11
90
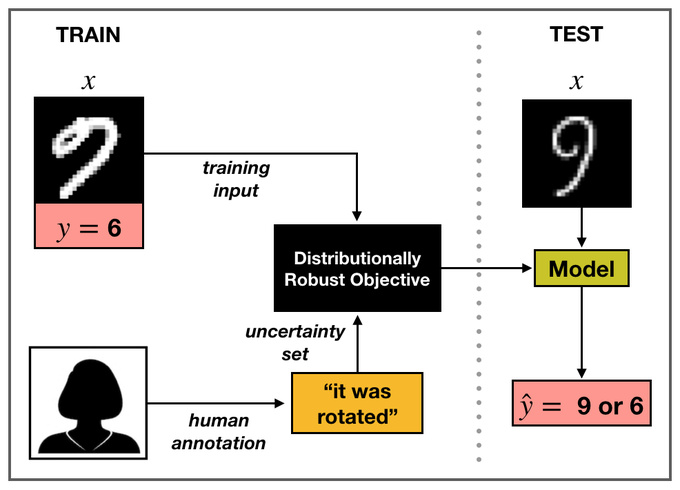
How can we be robust to changes in unmeasured variables such as confounders?
@megha_byte
shows that we can leverage human commonsense causality to annotate data with potential unmeasured variables.
Come by our
#ICML2020
Q&A at Jul 14, 9am and 10pm PDT ()!
0
5
81
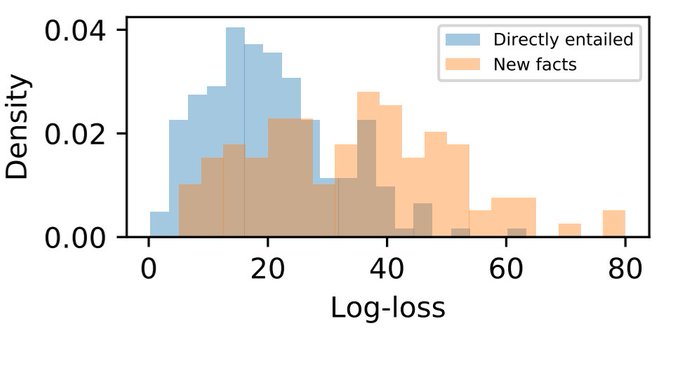
New work with
@daniel_d_kang
on improving training losses for more reliable natural language generation ().
Large scale corpora are often noisy and contain undesirable behaviors like hallucinating facts. The ubiquitous log-loss amplifies these problems. 1/2
1
14
70
This work would not be possible without
@MetaAI
’s open-source LLaMA, the self-instruct technique by
@yizhongwyz
et al,
@OpenAI
for their models and showing what can be achieved, and the team:
@rtaori13
@__ishaan
@Tianyi_Zh
@yanndubs
@lxuechen
@guestrin
@percyliang
4
3
68
Interested in evaluating generation? Want rigorous evaluations of model plagiarism and underdiversity? Come see "Unifying Human and Statistical Evaluation for Natural Language Generation" (w/ Percy Liang and
@hughbzhang
) on Tuesday 9:18 at Northstar A. ()
0
16
65
Alpaca has many flaws and open release can have negative effects, but we believe the benefits of open research outweigh the drawbacks. We discuss the decision for release on our blog and mitigate demo misuse through content filters and watermarks.
Blog:

2
4
59
Come see my students' ICML talks on SSL/LMs!
Studying what happens when models train on their own outputs (Oral B4,)
Quantifying opinions reflected by LMs (Oral B1,)
A new risk decomposition for SSL (Oral B5,)
0
10
51
NLG data can be noisy, and training on such data makes LMs replicate these issues. Can we trace and remove these examples?
Come to the contrastive error attribution poster at 11. I'll be there for
@faisalladhak
+
@esindurmusnlp
who couldnt make it (arxiv )

0
10
44
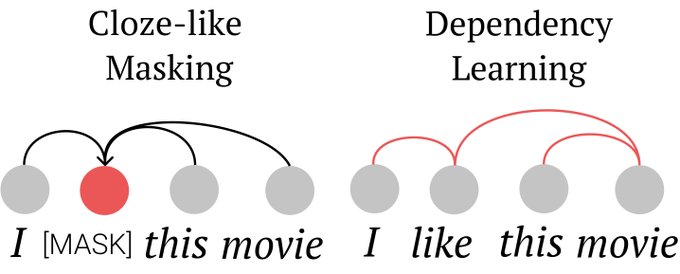
This was a really fun project - the observation that the conditional mutual information learned by BERT can be directly be used to do unsupervised dependency parsing was very neat and surprising.

Sharing my NAACL 2021 paper (w/
@tatsu_hashimoto
):
Why does random masking work so well in language model pre-training?
We show that MLM can capture the statistical dependencies between tokens and these dependencies closely mirror syntactic dependencies.
0
38
182
0
1
41
Posting model-generated content on the internet can end up degrading the quality of future datasets collected on the internet.
@rtaori13
did some neat work trying to study when this will / wont be a big problem.

🎉 The last few weeks have seen the release of
#StableDiffusion
,
#OPT
, and other large models.
⚠️ But should we be concerned about an irreversible influx of AI content on the internet?
⚙️ Will this make it harder to collect clean training data for future AI models?
🧵👇 1/6
1
14
79
1
7
34
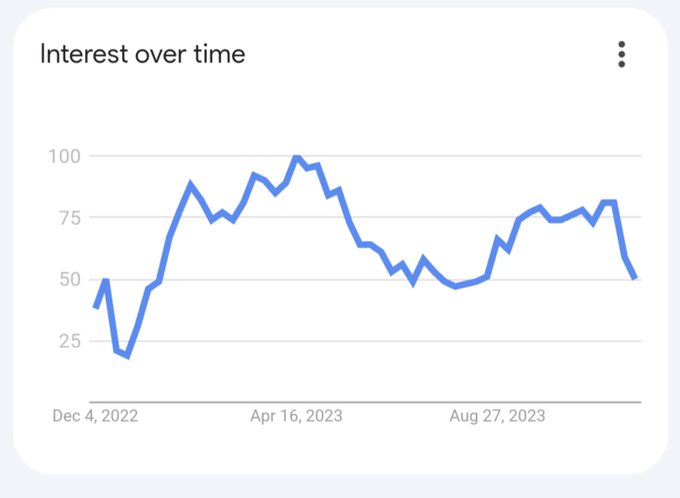
Is chatGPT now in a steady state rather than explosive growth? The Google Trends (US, 1-year, "ChatGPT" search term) is surprising and interesting. I expected a return to rapid growth once school was back in session.
5
1
33
Working on AI safety? Consider submitting to the ICML AI Safety Workshop!

🚀Thrilled to launch the Workshop on the Next Generation of AI Safety at
#ICML2024
! Dive into the future of AI safety. CFP & more details 👉
#NextGenAISafety
#ICML2024
1
1
15
0
5
31
@srush_nlp
We analyzed some of these data contamination and stability questions in a paper last year . Roughly, if you are indistinguishable (in a total variation sense), and you make stability assumptions on the learner, the dynamics are stable and not too bad.

2
2
31
Please help disseminate! Flexible post-doc position at SAIL working with research groups of your choice. Hopefully a useful opportunity for people waiting out the hiring freeze.

AI postdocs available! The Stanford AI Lab is trying to help in the current
#COVID19
pandemic. Some of that is via research but another need is jobs for great young people. We’re opening positions for 2 years of innovative research with Stanford AI Faculty

3
63
175
0
7
29
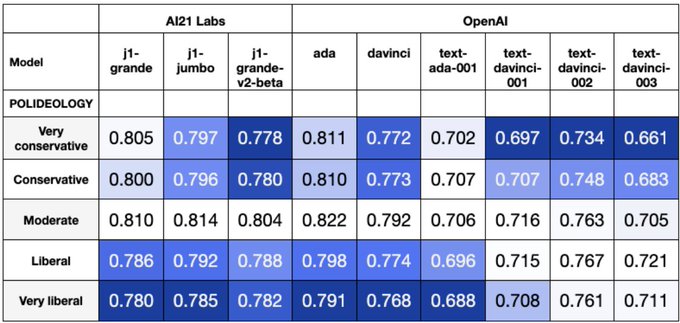
We also find that newer human-feedback tuned models are not only more left-leaning than base LMs, but often collapse onto the dominant liberal viewpoint (e.g., 99% approval for Joe Biden) and attempts to steer LMs towards specific groups lead to only modest improvements.
1
3
19
Great to see parameter efficient RL and simple changes to RLHF leading to better models on AlpacaFarm!

Happy to share our paper on aligning LLaMA 7B with LoRA-based RLHF!
LoRA uses 2 A100s compared to 8 for full model tuning, and yields higher win rate on AlpacaFarm with only 10h training ✅
More details below:

3
22
133
0
3
19
We create a new dataset of opinion polls, OpinionQA, and compare LM responses to those of 60 demographic groups in the US. With this, we can quantitatively and comprehensively characterize who current LMs are aligned to.

1
5
19
The core idea is a reduction from LM factuality to conformal prediction. We do this by associating each LM output with an 'entailment set' where the set containing any true fact implies correctness. Conformal prediction can then provide the necessary containment guarantees.
2
3
19
OpinionQA is now a part of HELM and you can get OpinionQA here (). We hope our work helps improve the broader discourse on opinions and values that LMs do or should reflect.
w/
@ShibaniSan
,
@esindurmusnlp
,
@faisalladhak
, cinoo lee, and
@percyliang

1
1
18
Neat way to incorporate unlabeled data into distributionally robust optimization (along with ). The duals work out surprisingly nicely (though convergence rates are probably still nonparametric).


Our foray into “robust learning” (and messy duality proofs!). Charlie noticed issues with DRL using transport (fig1) and developed a model/algorithm to address using additional unlabeled data. Algorithm is built on a hard-fought dual (thm2) worked out with Ed and
@sebastianclaici
2
3
14
0
1
16
Unbiased samples from a MCMC chain? This coupling + telescoping sum argument is really neat!

JRSSB discussion paper by Pierre Jacob, John O'Leary and Yves Atchadé on "Unbiased Markov chain Monte Carlo methods with couplings," 11 December 2019,
0
2
23
0
2
14
Replicating experiments in CS can be hard, but it turns out its nothing compared to what can happen in chemistry. Experiments that consistently work can *one day suddenly stop working, and never work again*
1
1
15
Our approach lets users target (almost) any probability level for correctness and factuality, and the LM attains nearly exactly this target correctness level (marginally over the calibration and test sets).
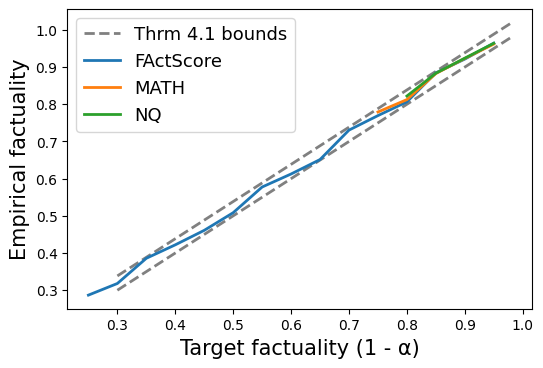
1
1
15
Fascinating claims and commentary. I was thinking of skimming a few pages and ended up reading all 52.

Why did I do that? 🤔 Today in lab meeting we discussed "Rationalization is rational" (). Thanks
@fierycushman
for a thought-provoking and beautifully written paper!
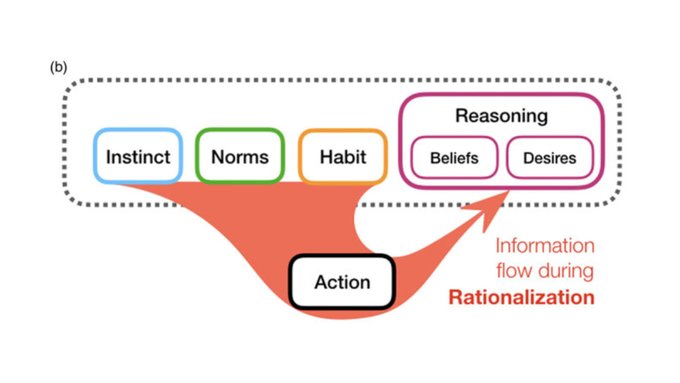
0
9
51
0
1
15
We find the RLHF simulator to be very accurate.
The simulated annotators are close to humans in agreement rate (65 vs 66%) at 1/45th the cost, and rankings of methods trained in simulation agree with rankings of methods trained on real human feedback.
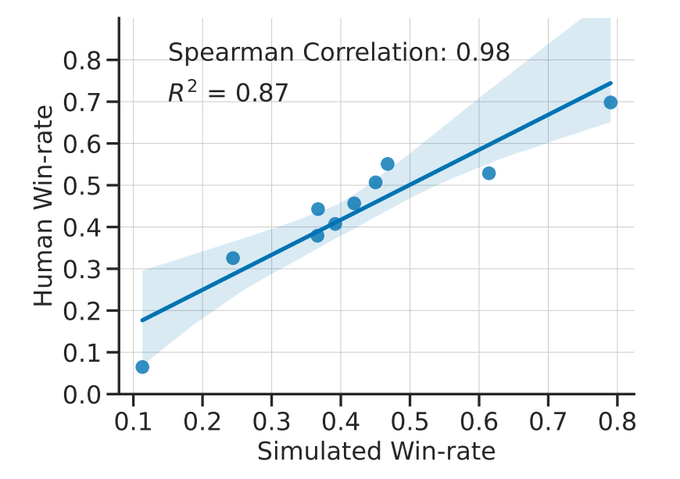
2
1
14
You should also check out the many other cool contamination-related papers at this ICLR like Shi et al (), Golchin et al (), and Roberts et al (). Each has a different take on this problem!
0
3
14
Finally, w/ the AlpacaFarm release, we are releasing easy-to-run code for the simulator and RLHF methods, as well as all 40k human and simulated preference data (data: , code: )

1
2
13
Work was done by
@yanndubs
@lxuechen
@rtaori13
@Tianyi_Zh
@__ishaan
JimmyBa
@guestrin
@percyliang
, at Stanford CRFM and
@stanfordnlp
and this work was made possible through compute grants from Stanford HAI and
@StabilityAI
2
1
13
Really well thought out and in-depth perspectives on making grad school decisions.

After talking to many students about their grad school experience I compiled this blog post on "How to pick your grad school". I discuss all the important factors and details from contrasting but complementary perspectives. I hope it will be helpful!
6
46
180
0
0
12
This one is a fun one to read, and the intro is refreshingly upfront about the limitations of this approach (log-n factors and high probability bounds).

A fantastic new paper by Thomas Steinke and Lydia Zakynthinou (
@shortstein
and
@zakynthinou
). They use Conditional Mutual Information as a perspective to understand generalization, capturing VC dimension, compression schemes, differential privacy, & more.
0
7
56
0
0
11
The resulting system is practical. Here are some random, non-cherry-picked outputs on FactScore, NQ, and MATH for a system providing 80% (FactScore) and 90% (NQ, MATH) guarantees.



2
1
10
We find that on topics from abortion to automation, there is a substantial misalignment between opinions in LMs and of these groups - as divisive as the Democrat-Republican divide on climate change and some groups (65+, mormon, widowed) are poorly reflected in all current LMs.
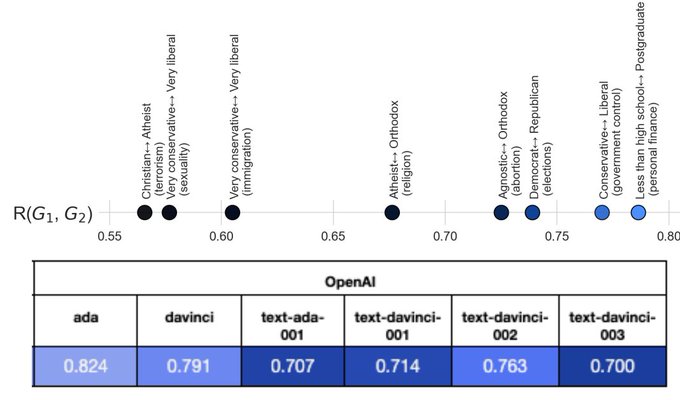
1
1
10
This may be one of my favorite ML blog posts - from
@BachFrancis
on sequence acceleration ().
0
1
10
On tasks like FactScore, NaturalQuestions, and MATH, we can take low to moderate base factuality levels (<30% for FactScore, <80 for others) and boost them to 80-90% factuality while keeping most of the LM outputs.
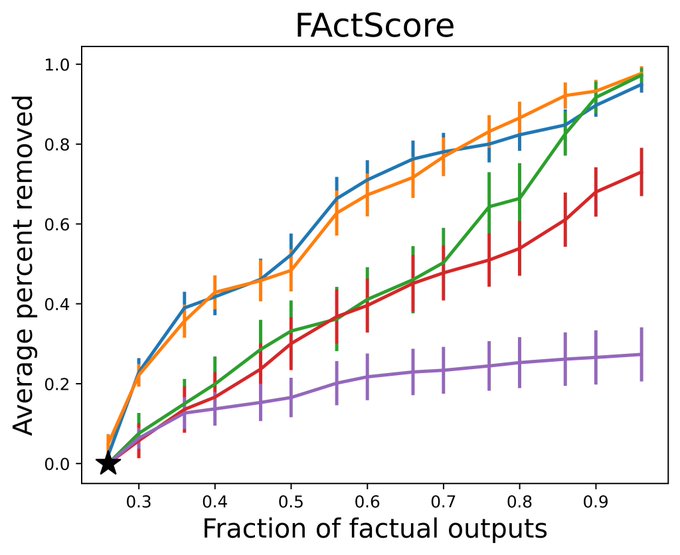
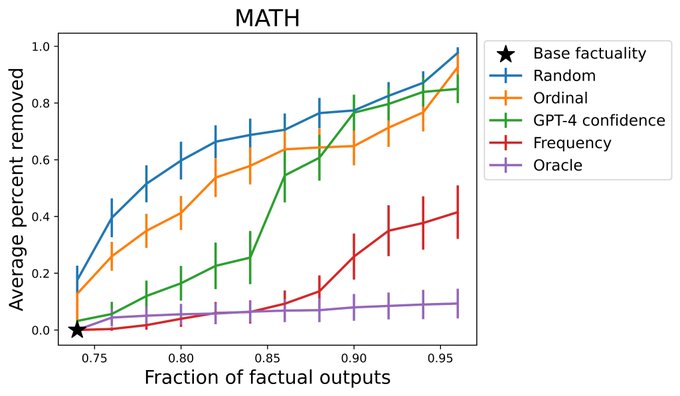
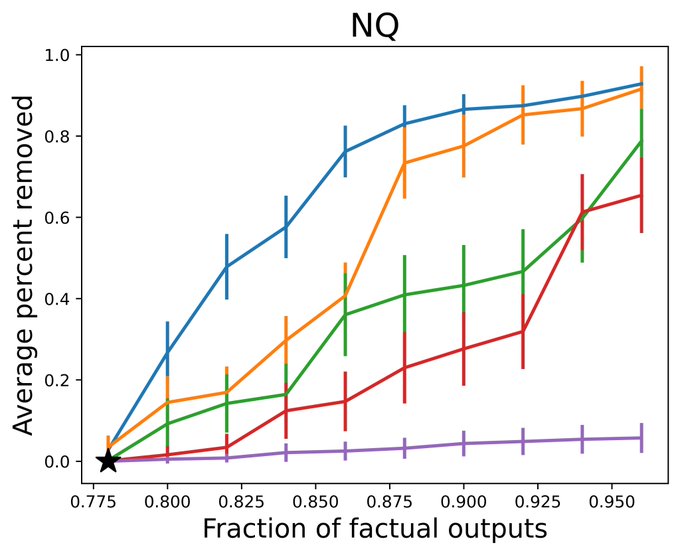
1
1
9
Please see our paper for other details, like how it’s necessary to emulate inter- and intra-annotator variability to build a simulator that captures important phenomena like overoptimization ()
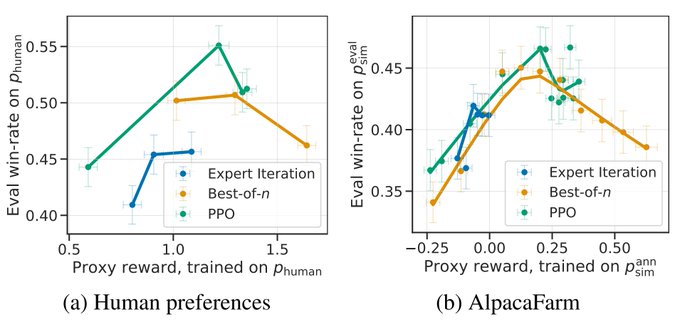
3
0
9
This is since log-loss prevents models from assigning zero probability to noisy test sequences.
Adaptively truncating the loss solves this by optimizing for model distinguishability. Empirically, we find improvements in factuality for Gigaword summarization 2/2.
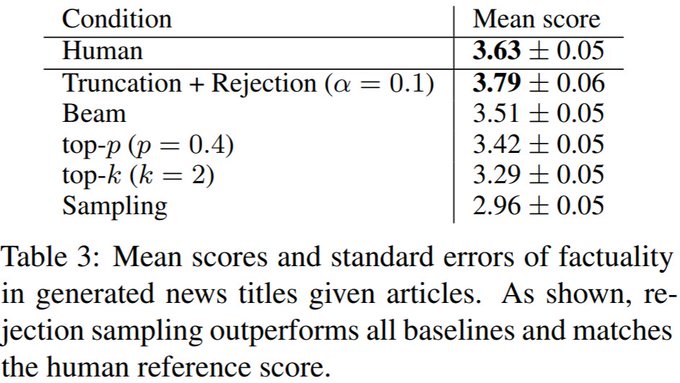
0
0
8
Additionally, to enable fast and reproducible evals, we define a new automatic eval for instruction following and combine many existing eval datasets. This aggregated eval set agrees very well with the simple but real human instructions from the Alpaca live demo.
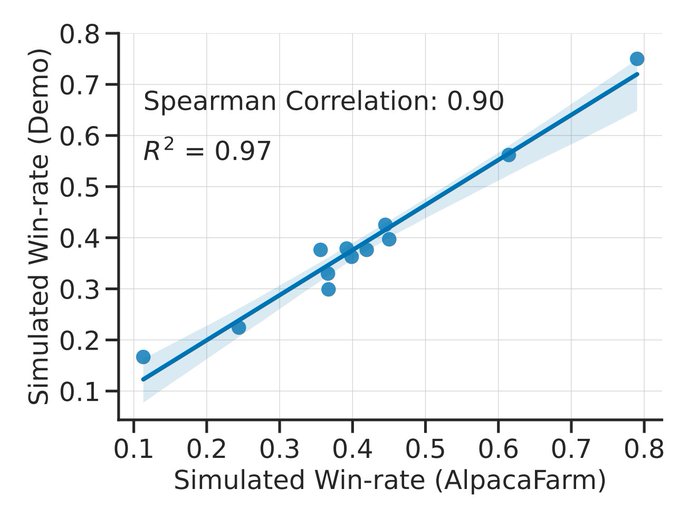
1
0
9
Our reference RLHF implementations give substantial improvements. The best method (PPO) provides major gains over Alpaca on win rate vs davinci003 (41->55%), and we find it gives much more detailed explanations for answers.

1
0
8
@BlancheMinerva
@AiEleuther
Funny story is that we started with the pile, but didn't find test sets (at least large, exchangeable ones) so we trained our own positive control with contaminants. Pile and pythia is great for this kind of work, but we needed a lower quality, contaminated dataset for our expts
1
1
7
Our insight is that models memorize the order of examples seen in training. Since most datasets are exchangeable (order doesn't matter), a preference for a canonical ordering may indicate prior exposure: the model could only know the ordering if it saw the data during training.

1
1
7
Running this test on open models, we find little evidence that these LMs strongly memorize benchmark test sets. The exceptions are Mistral on ARC, and both LLaMA and Mistral on MMLU but these could be due to multiple hypothesis testing. See the paper for detailed discussions.
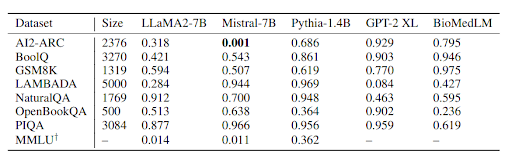
0
0
7
Our test can reliably detect benchmarks that are included more than once in a controlled experiment where we pretrained models with known contamination, with 100% success rate at duplication rates above 10, and 50% success at rates above 2.
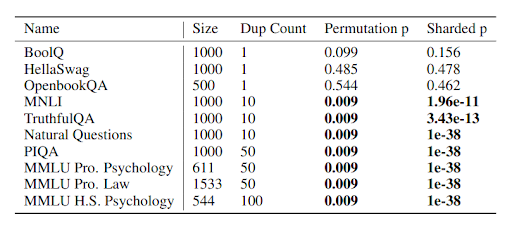
1
0
5
It's a few lines of code () to make huggingface transformers (BERT, GPT2, etc) differentially private.
The library also has nice memory tricks by
@lxuechen
to scale DP-SGD to large language models.
(contd)

1
1
5
@lxuechen
100% of the credit goes to whoever made . github actions is like putting lego blocks together.

0
0
4
@soldni
@SemanticScholar
The author API is a real gem. Very easy to match on desired authors or filter for basic author stats. I wish I could use the
@SemanticScholar
API for the ArXiv feed update part too, instead of hitting the ArXiv RSS endpoint.
0
0
4
@haileysch__
Our cost estimates of naively running this on text-davinci-003 across all the benchmarks we wanted was a bit terrifying. We do have ideas on dealing with this, and hopefully will have more positive things to say soon.
1
0
4
On the DP side: we surprisingly observe no 'curse of dimensionality' with large pretrained models, and DP-SGD improves as models get larger!
Often the baseline of DP-SGD over all parameters beats parameter-efficient methods.
(contd)
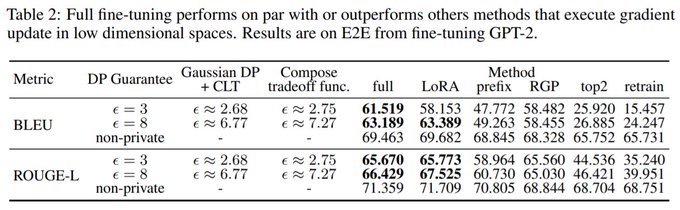
1
0
4
0
0
4
This was work with
@lxuechen
,
@florian_tramer
,
@percyliang
.
You should also check out (thanks to
@thegautamkamath
for an earlier shoutout to our work)
They show that you can also get high-performance private models using low-rank tuning methods.

0
0
3
On the private NLP side, we show provable privacy is easy:
Fine-tuning language models with DP-SGD nearly match nonprivate performance for a wide range of tasks, spanning classification, table2text generation, and dialog generation.
Want to try it? (contd)
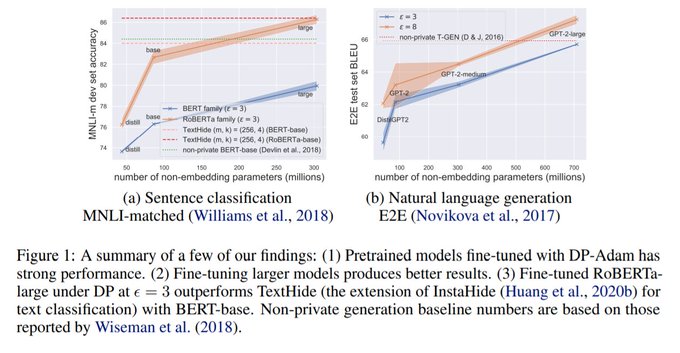
1
0
2
@jiajunwu_cs
@StanfordAILab
@Stanford
@StanfordSVL
@StanfordHAI
Welcome!! Looking forward to having you join!
0
0
2
@gabemukobi
Human (Chris) generated. The correctness annotation is from being technically true (correct but irrelevant). Our guarantees are always w.r.t the annotator, so technically all guarantees are "Chris would judge 90% of this as correct"
1
0
2
@BlancheMinerva
@haileysch__
The naive (non shared) version was something like 10k per dataset.. but I think we just have a fundamentally better design for this now, so I may reach out if we manage to find something a bit better and viable.
0
0
2
@lreyzin
@ben_golub
This seems like a variant of the Reichenbach common cause principle, which is pretty interesting stuff. It has some pretty extensive discussion and purported counterexamples here -
1
0
1
@RylanSchaeffer
@afciworkshop
@rtaori13
@sanmikoyejo
@stai_research
@StanfordAILab
@StanfordData
Cool! Seems like an important question here is how fine grained the calibration is. Calibrated only on the bias metric itself -> lots of room for amplification on the tail. Calibrated on all measurable functions -> fully stable. Reality is probably in between?
0
0
1
@srush_nlp
I think it's nuanced. You might have learning algorithms that don't have the right stability properties, and a second risk is the human data distribution changes from exposure to LLMs, and/or humans stop producing content, removing the stabilizing effect of human data.
1
0
1
@srush_nlp
@sebgehr
@fernandaedi
@mrdrozdov
Is the film a lot nicer than writing normally on the tablet? I can never get used to doing math on the tablet because of how the pen glides on the screen.
2
0
1
@ml_angelopoulos
@Eric_Wallace_
I don't think Chris is twitter active but I'll send him this thread. Section 3.3 in conformal risk control was quite nice and a good inspiration for us.
1
0
1