

Wei Xu
@cocoweixu
Followers
9,130
Following
1,240
Media
127
Statuses
1,197
CS professor @GeorgiaTech @gtcomputing @ICatGT @mlatgt . Natural language processing, machine learning, social media research.
Atlanta, GA
Joined January 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Claudia Sheinbaum
• 488749 Tweets
BB X LISA
• 210460 Tweets
増山さん
• 163162 Tweets
増山江威子さん
• 152167 Tweets
NORAWIT and KND
• 85672 Tweets
#CDTVライブライブ
• 65529 Tweets
Venom
• 57601 Tweets
エミリエ
• 49198 Tweets
音楽の日
• 36706 Tweets
God Kabir Prakat Diwas 22June
• 35643 Tweets
Emilie
• 25840 Tweets
#アンメット
• 25605 Tweets
ベンチマーク
• 25420 Tweets
Başın
• 22268 Tweets
Alpine
• 21763 Tweets
더보이즈
• 21624 Tweets
しゅごキャラ
• 20814 Tweets
Ocon
• 18712 Tweets
IS:SUE
• 16594 Tweets
Justin Jefferson
• 13418 Tweets
ヴェノム
• 12179 Tweets
STELL IS COMING
• 11489 Tweets




















Extremely excited to share this new work!
It introduces a systematic way to assess LLMs’ favoritism towards Western culture.
All LLMs (GPT-4, Aya, mT5, etc.) show favoritism, even when:
- prompt in non-English
- pre-training fully on non-English data

10
91
446
I am recruiting 1~3 PhD students in CS or ML to join NLP X lab at Georgia Tech.
Topics include but not limited to:
(1) multilingual multimodal LLM
(2) RLHF, text generation models
(3) NLP+X (X = privacy, science, etc)
Apply by Dec 15:
(📷Colin Gough)

10
89
420
I'm recruiting two new PhD students to join my lab at Georgia Tech. Possible areas of research include language generation, robust NLP, information extraction, interactive machine learning, etc.
#NLProc
Apply by Dec 15 (
@gtcomputing
CS/ML PhD program):
6
146
398
I am finally jumping on the bandwagon of GPT-3 and read the 72-page long paper released by
@OpenAI
. Here is a summary of some technical details:
Model: largely the same as GPT-2, but alternate between dense/space attentions as in Sparse Transformers (OpenAI's 2019 work).
1/n
4
74
376
Instead of spending too much time on Twitter, I decide to put some energy into learning to cook Indian food at home. Results are better than expected.
#pandemic
#Productivity



10
2
356
🙌 We are releasing GigaBERT (
@emnlp2020
paper) 🙌
A customized bilingual BERT for Arabic NLP and English-to-Arabic zero-shot transfer learning. Better performance than mBERT, XLM-RoBERTa, AraBERT.
#nlproc
Preprint:
Huggingface:

9
55
343

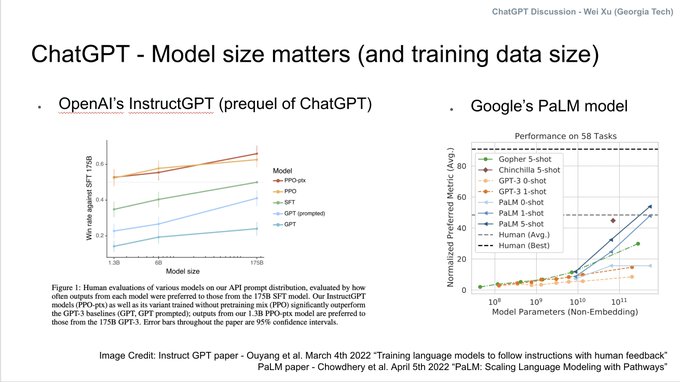
I got a lot of questions from friends, family, colleagues, and journalists (basically everyone I met) about
#ChatGPT
lately, so I made some slides to explain ...



4
65
293
Oh yeah!
“MADAM Vice President”
#NLProc
researchers — does this new phrase unseen in your training data break your NLP system?
#genderbias
#fairAI
4
30
256
The best paper award of
#acl2020nlp
plus one honorable mention goes to work that rethinks our experiment and evaluation methodology. Proud of the NLP research community which is capable of self-reflection and cares about real-world impacts.


0
45
258
I am also recruiting NLP research MS students doing the thesis option at Georgia Tech, located in Atlanta — a vibrant large city in the U.S., warm climates, hosted summer Olympics in 1996
(please apply & send me an email about your research interests)
I am recruiting 1~3 PhD students in CS or ML to join NLP X lab at Georgia Tech.
Topics include but not limited to:
(1) multilingual multimodal LLM
(2) RLHF, text generation models
(3) NLP+X (X = privacy, science, etc)
Apply by Dec 15:
(📷Colin Gough)
10
89
420
7
48
235
Teaching the 90-person graduate-level NLP class today. I was worried. But, every single student in the classroom had their mask on! No need to even ask or suggest. Very proud of
@GeorgiaTech
students.
2
1
221
One interesting finding of our paper is that a potential cause of cultural biases in LLMs is the heavy use and upsampling of Wikipedia data in pre-training of almost all LLMs.
More Western cultural concepts are written about in non-Western languages, than the other way around.

Extremely excited to share this new work!
It introduces a systematic way to assess LLMs’ favoritism towards Western culture.
All LLMs (GPT-4, Aya, mT5, etc.) show favoritism, even when:
- prompt in non-English
- pre-training fully on non-English data
10
91
446
1
34
200
Let's talk about high-quality inspiring work!
My favorite NLP papers in 2022-23 are:
Diffusion-LM Improves Controllable Text Generation
Lisa Li et al.
Nonparametric Masked Language Modeling
Sewon Min et al.
What's yours?
1
19
171
The first week of my fall semester
@GeorgiaTech
--
1) teach grad NLP w/ a full waitlist
2) chase late reviews as SAC for EMNLP
3) help students to write rebuttals
4) recruit 3 undergrads
5) welcome 5 new PhD students to NLP X Lab 🔥
6) exciting research discussions/meetings
2
4
153
Our new work on automatically extracting COVID-19 events from Twitter. We annotated 7,500 tweets annotated with event QA/slot-filling information. (e.g., Who tested positive? Who is promoting a cure for coronavirus?)
#nlproc
Paper:

4
27
155
Didn’t know that I was one of the outstanding Area Chairs for
@emnlp2020
— thanks! That made my day 🤓
2
0
152
I am giving a talk at
@USC_ISI
tomorrow on "Natural Language Understanding for Noisy Text"!
Here is a sneak peek of the talk outline 😎 --

5
11
146
My phd
#1
@JeniyaTabassum
successfully defended today! (co-advisor
@alan_ritter
)
Her thesis explored the space of "Information Extraction From User-generated Noisy Texts" -- Twitter, StackOverflow, wet-lab protocols!
#nlproc
A live demo of her work:
5
3
143
ACL 2020 paper on automatic evaluation metrics for MT and generation by
@ThiboIbo
@dipanjand
@ank_parikh
My takeaway -- my current top choices of metrics are:
1) BLEURT (trained on human ratings)
2) SARI (for text-to-text generation)
3) BERTScore w/ RoBERTa
#nlproc
5/n

2
27
139
I am looking for PhD students in natural language processing and machine learning: Please RT!
#nlproc
2
135
125
I am super proud of this human-centered AI work from my students and NLP/HCI/Privacy collaborators at Georgia Tech and CMU.
It allows users to take control of their own contents, preventing private information ends up in LLM's pre-training data.
Paper:


Ever wondered “Am I oversharing on social media?”, and worried about privacy risks?
In our new paper, we use language models to pinpoint self-disclosures and provide diverse abstractions for users to choose from. All of these are backed and motivated by a real-world user study!

1
5
39
4
16
123
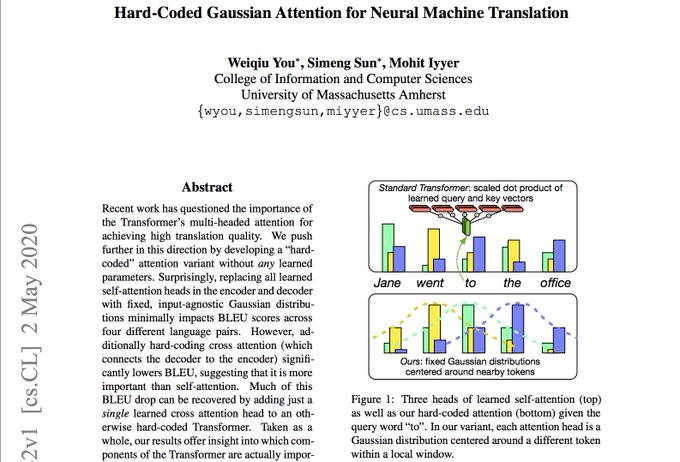
ACL 2020 paper on understanding the Transformer model by
@youweiqiu
, Simen Song,
@MohitIyyer
My takeaway -- replacing learned self-attention w/ a fixed hard-coded Gaussian attention works surprisingly well for MT.
My question -- Does this hold for non-MT tasks?
#nlproc
4/n
7
26
121
Work by my phd student
@mmaddela1005
on controllable text generation accepted to NAACL 2021!
1) inject linguistic knowledge into neural networks
2) control 3 types of edits - sentence splitting, deletion, paraphrasing
3) large, clean training data

1
16
120
I wrote an ultimate Twitter API tutorial:
http://t.co/WFOICO33f5
#datascience
#nlproc
@twitterapi
http://t.co/3npagqRZPo
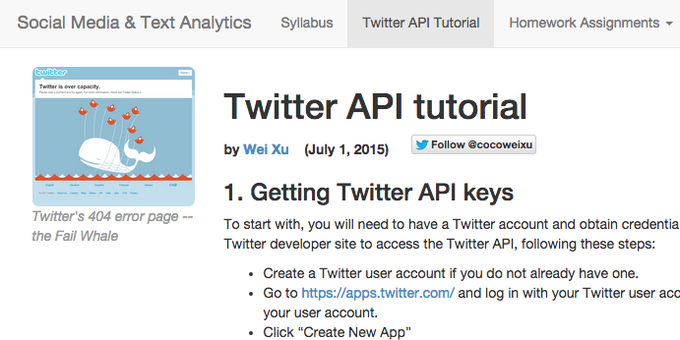
7
48
121
My students from *NLP X lab* at Georgia Tech and collaborators will be presenting 6 papers at ACL 2023 in Toronto next week! See everyone there!
#nlproc
#acl2023nlp
@mlatgt
@ICatGT
They cover a diverse set of topics (5 in main conference, 1 in findings):
1/3
1
15
120
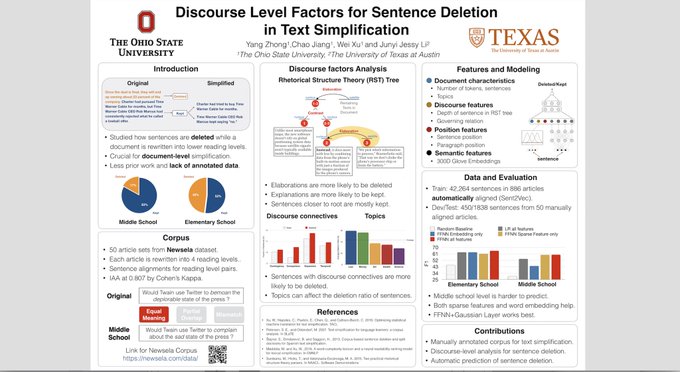
1
19
111
We all know LLMs hallucinate and make other errors in their generated texts. My student made an interactive tool Thresh🌾to help humans spot and flag them more easily!
It can be customized for your own tasks (MT, summarization, text revision, + more) and evaluation criteria.

Evaluating text generation is difficult — span-based evaluation is robust, but tough to build. 🤔
Introducing Thresh 🌾 — a platform for universal, customizable and deployable fine-grained evaluation for text generation!
🖥️
📝
1
17
95
2
14
101
ACL has removed the anonymity period to allow authors to post work on arXiv at any time before/after submission.
This covers “*ACL conferences (ACL, NAACL, EACL) and the TACL journal”.
Thanks to many people who have put a lot of energy into this!

ACL announcement:
"The ACL Executive Committee has voted to significantly change ACL's approach to protecting anonymous peer review. The change is effective immediately. (1/4)
#NLPRoc
5
189
443
1
8
98
My NLP research group meeting up w/
@alan_ritter
’s group
@GeorgiaTech
😷🐝🐝
looking forward to an exciting new semester!
@mlatgt
@gtcomputing
#nlproc

0
1
92
ACL, NAACL, EMNLP officer election —
Instead of having a statement, we should ask candidates for their stances on the important, concrete issues:
* anonymity deadline
* PC chair candidates they will nominate
* transparency of the board
* ARR
#ACL2023NLP
#NLProc
2
7
91
Want to learn more about multilingual LLMs at
#ICLR2024
? Find us at poster
#64
— with
@alan_ritter
and
@DuongLe54055716

3
7
91
I just sent a note to NAACL board to try to put removing anonymity deadline for NAACL conference into a vote.
Sorry, I should have done this sooner. But it requires two members (not only one) in order to put a motion into the vote … non-trivial task.

Just got a desk reject, post-rebuttals, for a paper being submitted to arxiv <30 min late for the anonymity deadline. I talk about how the ACL embargo policy hurts junior researchers and makes ACL venues less desirable for NLP work. I don’t talk about the pointless NOISE it adds.
28
47
404
4
3
87
It turns out that my vote in Georgia is even more important than I expected. (and even more important than voting in Ohio)
#Election2020
3
0
82
Website for the WNUT workshop at EMNLP 2021 is now live!
This is the 7th year we are running the Workshop on User-generated Text. We are glad to see this research community continues to grow.
#nlproc
@emnlpmeeting
Please RT and submit your work!
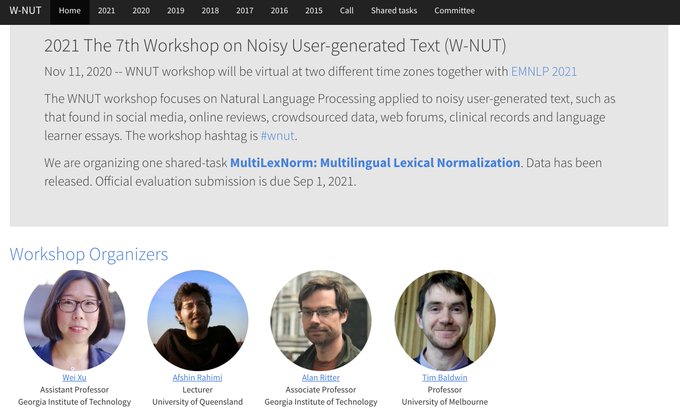
0
18
80
ICLR 2024 paper led by
@DuongLe54055716
that unlocks multilingual LLM's capability to perform NLP tasks in 20 African languages, and more.
#ICLR2024
* outperform GPT-4 on zero-shot
* add punctuations to translation input
+ constrained decoding
Paper:
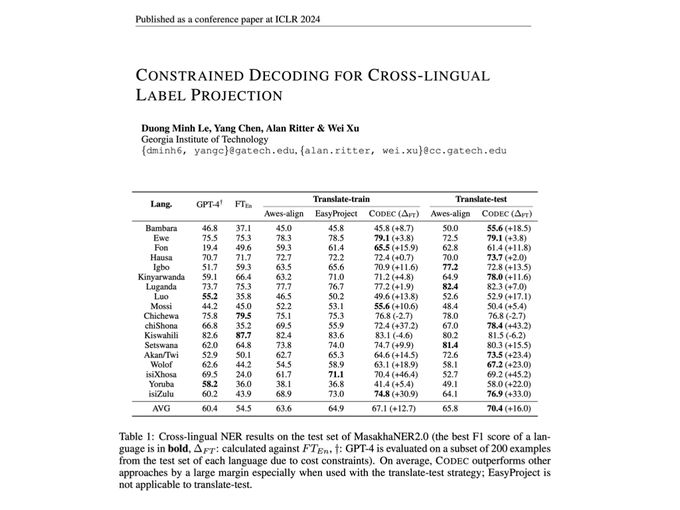
1
12
80
There were only ACL and EMNLP last year. This year has NAACL, ACL, EMNLP, EACL, COLING, AACL, LREC ... plus AAAI, ICLR, NeurIPS for
#NLProc
. Writing paper doesn’t seem to be a problem, but how are we holding up for reviewing and area chairing?
4
2
78
A lot of appreciation to organizers of virtual conferences. I miss the easy navigation of EMNLP 2020 website, the dedicated Zoom link for each paper at two separate hours to easily find specific authors, and RocketChat.
#NLProc
1
3
78
0
0
76
I had a great time visiting UCLA and USC during the spring break to give talks on "Amazing Multilingual Capabilities and Concerning Cultural Biases in Large Language Models".
Thanks to
@_jessethomason_
@VioletNPeng
@kaiwei_chang
@robinomial
for hosting!



1
8
78
I'm running for the NAACL board and hoping to increase students' opportunities to present work and meet other NLP researchers (countering impacts from pandemic/cost/visa, etc).
Please vote by Dec 31 via ACL member email titled "NAACL Board Election".

NAACL 2023-2024 election has been launched!To vote by Dec 31, login with the Voter ID and Voter Key you should have received in an email at the address you used to register as a NAACL member. Candidate statements at:
0
3
7
3
10
72
Great to have Noah Smith
@nlpnoah
talk at Georgia Tech today about open-source LLMs trained with open-source pre-training data (OLMo model by
@allen_ai
) for the Distinguished Speaker Series.
photo credit: Nathan Deen
@ICatGT
host:
@kartik_goyal_


1
2
73
EMNLP 2020 Workshop on Noisy User-generated Text (W-NUT) is organizing three shared-tasks this year!
@emnlp2020
#nlproc
Call for participation. Please RT.
More details:

1
25
71
EMNLP will be held in Brussels, Belgium on October 31 - November 4th, 2018; ACL 2019 will be held in Florence, Italy July 28 – August 2, 2019.
#nlproc
#europetrips
0
28
69


ACL 2020 paper on semi-supervised learning by
@jiaao_chen
, Zichao Yang,
@Diyi_Yang
My takeaway -- 1) interpolate hidden layers in Transformer to create pseudo labeled data. 2) KL-divergence plus self-training loss to utilize back-translations as unlabeled data.
#nlproc
6/n

1
6
67
Working on social media data, medical records, student essays, customer reviews, etc.?
#nlproc
#socialmedia
Consider submitting a paper (4 or 8 pages, due Aug 19) to the COLING 2022 Workshop on Noisy User-generated Text (W-NUT) --
2
13
61
We present a cooking chatbot 🧑🏼🍳 ChattyChef!
We talk about chatbots and personal assistants, but not yet have a dialog task that is:
- document-grounded, goal-oriented
- multi-step procedural knowledge + commonsense
- useful & fun!
#ACL2023NLP


Looking for an
#AI
Sous Chef?
@gtcomputing
experts created a dataset called ChattyChef to help in the kitchen. Using the open-source
#LLM
GPT-J, ChattyChef’s dataset of cooking dialogues follows recipes along with users.

2
5
11
1
5
61
@bkeithpayne
Do and Don’t to PhD students:
1) Don’t focus on classes, focus on research!!
2) Focus on getting important (often more difficult) things done; other than wasting time on simple but less important things.
3) Don’t give up a project without really trying very hard.
1/
2
5
56
.
@gregd_nlp
has a great sequence of slides for a hard-core NLP class — my current favorite. I also like
@yoavartzi
,
@gneubig
, and
@stanfordnlp
’s
#NLProc
teaching materials.

First CFP Teaching NLP Workshop
2 day workshop:
- day 1 working groups
- day 2 talks/keynotes/panels
2 submission types (due mar 15):
- teaching materials
- papers (any length, 4-10 pgs preferred)
#nlproc
#NAACL2021
#TeachingNLP
0
16
36
1
6
55
This wonderful data visualization created by Joshua Preston shows the popular topics and author's geolocation distribution for
@aclmeeting
#ACL2023
.
Top tracks:
- NLP Applications (81 papers)
- Machine Learning for NLP (75 papers)
- Information Extraction (72 papers)

0
8
54
News from the
#NAACL
exec board to share:
* We uniformly agreed to release meeting minutes publicly
Thanks to chair
@LucianaBenotti
for the 10 minutes at the board meeting today to discuss transparency! We think we have some ideas on how to improve, one step a time😊
0
1
54
Surprisingly little work has used neural networks to measure word/phrase complexity & language styles. Our new
#EMNLP2018
paper provides a neural ranking model that vectorizes numerical features & a word-complexity lexicon of 15,000 English words.
#nlproc
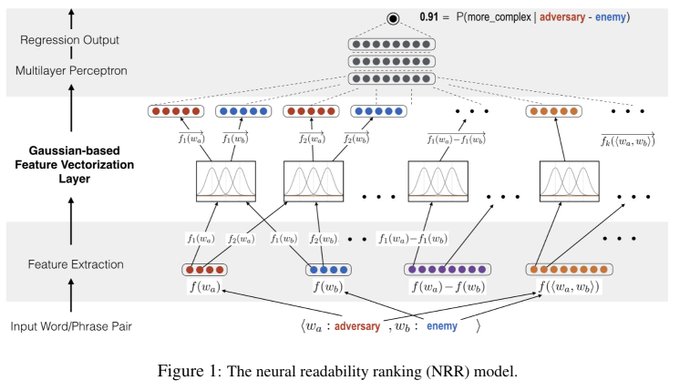
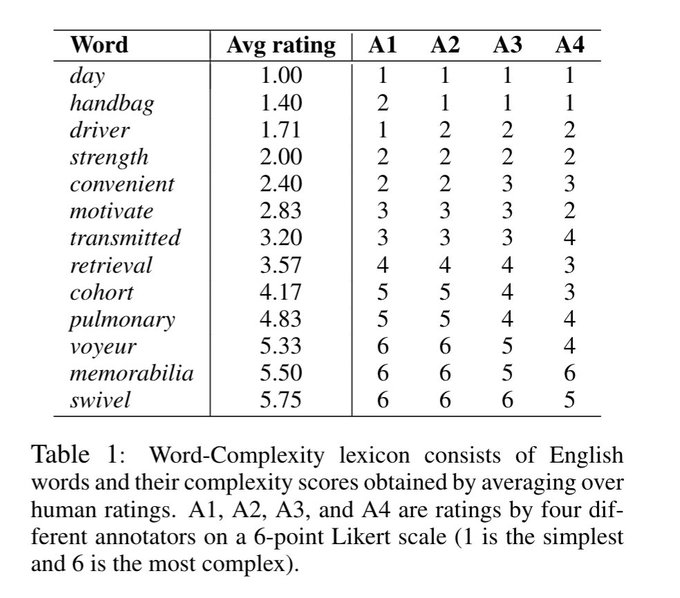
0
7
53
How to choose PhD offer if you've been admitted into multiple programs? - a practical guide by Andrew Kuznetsov (
@andrewkuznet
)
#phdlife
#phdadvice
Full Resolution PDF👉

0
7
51
I condensed my semester-long CS course "Social Media & Text Analysis" into a 45-minute tutorial for high school kids.
Going to debut it at High School I/O
@hackohio
this Saturday! 😀
#NLProc
#Python
@OSUOutreach
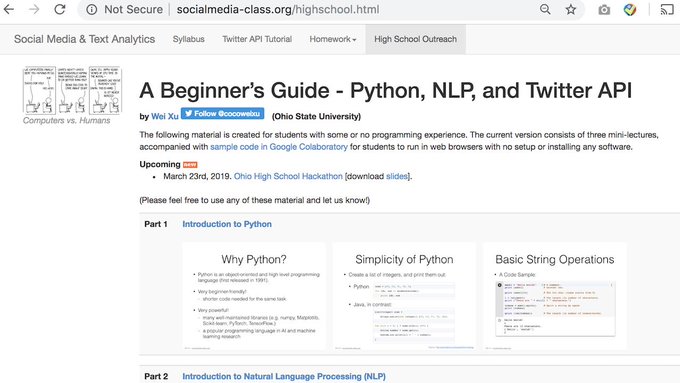
0
8
51
Good advice, people! Read if you are reviewing for EMNLP/ACL/NAACL/TACL ...
You should not reject a paper if you can understand the paper and it seems simple. You should not accept a paper if it only appears to be complicated and makes you feel it is "technical".
#nlproc

New blog post on reviewing policies!
Special focus on spurious reviews: this time no paper should be rejected primarily for not beating SOTA, for non-English work, for being a resource paper, etc. /1

9
267
795
0
6
51
Excited to give a talk at
@LTIatCMU
Colloquium tomorrow about our recent work on controllable text generation, creating high-quality parallel training data, and automatic evaluation metric.
#nlproc
(work w/ my PhD students
@mmaddela1005
@chaojiang06
)

1
3
50
EMNLP workshop on noisy user-generated text (WNUT 2019) looks for long/short research paper submissions, as well as 1-page abstracts on work-in-progress or previously published work. Submission deadline - August 19.
#emnlp2019
#nlproc
#wnut
Website:
2
13
49
Looks like
#acl2020nlp
is going to organize several extra mentor sessions tomorrow (July 8 12-1 PDT). I signed up to host another session of "Whether to do a PhD and how to apply for and choose a PhD program". DM me if you want to co-host or need the Zoom link to attend.
9
5
48
I applaud EMNLP’s efforts to educate the reviewers and steer the field to focus more on meaningful research other than just beating SOTA numbers.
In particular, SOTA RESULTS ARE NEITHER REQUIRED NOR SUFFICIENT. Progress is made in papers which people can learn from. There should be a clear hypothesis, and the authors need to show that the results are due to their contribution, and not some external factors.
2
26
186
0
2
48
So true 🤣🤣🤣 I feel my students can relate

0
3
46
I will be at ACL 2023!
Email me (wei.xu
@cc
.gatech.edu) if you want to meet up and say hi, discuss research collaborations, or have questions about research MS and PhD admission of Georgia Tech, etc.
#ACL2023NLP
#nlproc
My students from *NLP X lab* at Georgia Tech and collaborators will be presenting 6 papers at ACL 2023 in Toronto next week! See everyone there!
#nlproc
#acl2023nlp
@mlatgt
@ICatGT
They cover a diverse set of topics (5 in main conference, 1 in findings):
1/3
1
15
120
1
3
47
Got my 1st dose of Pfizer vaccine on
@GeorgiaTech
campus today! 👌Appointments are now open for all students, staff, and faculty members.
0
0
45
ACL 2020 paper on "Sandwich"🥪Transformer by
@OfirPress
@nlpnoah
@omerlevy_
My takeaway -- With rearranged self-attention and feedforward layers, Transformer model can perform better on language modeling, but not MT.
My question -- fixed hyperparameters?
#nlproc
9/n

3
0
45
why and how we should care about good science -- nice post from
@EhudReiter
-- surprised to see so few retweets, or perhaps, that is part of the problem.

On the importance of good, appropriate data sets for
#NLProc
, but how “the system” tends to wrongly incentivize researchers.
1
90
243
3
10
43
Got some photos from my colleagues. Can't wait to go back to work in offices in the CODA building, where the NLP group
@GeorgiaTech
(part of
@mlatgt
) is hosted.


4
3
43
Paper titled "Multi-task Pairwise Neural Ranking for Hashtag Segmentation" w/ my phd student Mounica Maddela and
@Bloomberg
co-author
@daniel_preotiuc
is accepted at ACL 2019!
#nlproc
#ACL2019nlp
--> "ACL 2019 nlp"
Preprint:
(Code/data coming soon!)
0
0
44
We are watching the ACL tutorial (open-domain QA by
@scottyih
and
@danqi_chen
) live on the living room TV while eating dinner.
#acl2020nlp
5
0
42
A major effort from my group to advance NLG research to appear
#acl2020nlp
:
"Neural CRF Sentence Alignment for Text Simplification"
We create a much larger higher-quality corpus w/ neural CRF alignment + Transformer for SOTA generation results.
preprint

0
3
41
First time having not only name but also **emoji** clashes in NLP?
My student’s ACL 2023 paper is on LENS 🔎 - a learnable evaluation metric for text simplification …


Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
Finds that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever.

4
79
302
3
1
42
Welcome new faculty member
@kartik_goyal_
to join Georgia Tech’s growing NLP group!
@ICatGT
@mlatgt
#NLProc
Together (w/ me &
@alan_ritter
), we expect to recruit several PhD students in NLP/LLM for the coming year.
Please apply!
(due Dec 15)

🚨 I started as an assistant professor at Georgia Tech
@ICatGT
this fall! I am looking to hire PhD students interested in NLP, ML, and cultural analytics (LLMs inlcuded 😉). Come work with me! Apply to a PhD Program listed here and mention me in your app: .
20
23
201
1
1
42
A single span-based neural model that produces SOTA results for many NLP task (from constituent parsing to NER to OpenIE, etc.) — strongly recommend everyone start using this, instead of naive fine-tuning BERT, as the strong baseline in upcoming
#nlproc
papers!

New
#acl2020nlp
paper on "Generalizing Natural Language Analysis through Span-relation Representations"! We show how to solve 10 very different natural language analysis tasks with a single general-purpose method -- span/relation representations! 1/
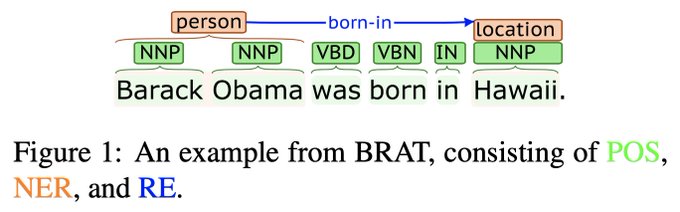
2
51
241
1
7
40
Workshop on Noisy User-generated Text (WNUT) at EMNLP 2021 has received 69 submissions & will have best paper awards sponsored by
@TechAtBloomberg
.
Thanks to 177 PC members from 15+ countries (many with a new affiliation, congrats!)
@emnlpmeeting
1
2
41
Best paper awards at Noisy User-generated Text Workshop
@emnlp2018
go to researchers from
@EdinburghNLP
and
@Grammarly
(thanks to
@MSFTResearch
sponsorship)
#nlproc
#wnut

0
9
40
#NAACL2021
paper on controllable text generation (text simplification, paraphrasing, splitting)-- will be presented tonight around 6:20pm PST / 9:20pm EST / 11:20pm BST in Zoom 10C-Language Generation.
Underline --
Work by my phd student
@mmaddela1005
on controllable text generation accepted to NAACL 2021!
1) inject linguistic knowledge into neural networks
2) control 3 types of edits - sentence splitting, deletion, paraphrasing
3) large, clean training data
1
16
120
0
3
39
ACL 2020 paper on distant supervision for document-level QA by Hao Cheng,
@mchang21
@kentonctlee
@toutanova
My takeaway -- Devil's in detail. What exact distant supervision assumptions you r making, paragraph vs doc, position vs span, max vs sum. They all matter.
#nlproc
7/n

1
5
38
ACL 2020 paper on image captioning by
@malihealikhani
, P. Sharma,
@shengjie_nlp
@RSoricut
, M. Stone.
My takeaway -- a new dataset of 10,000 image captions labeled for describing visible/subjective/imaginary/off-the-scene elements, leading to better generations.
#nlproc
10/n

2
7
36
I will be in Vienna for
@iclr_conf
next week. Happy to talk about multilingual LLMs, cultural bias and adaptation of LLMs, pre-training data, evaluation of LLMs-generated text, privacy preservation, etc. DM me.
Image and data visualization credit - Joshua Preston
@gtcomputing

We have deep roots in deep learning, which uses algorithms inspired by the structure and function of the brain's neural networks. Take a deep dive into our experts' new deep learning research at
@iclr_conf
(May 7-11) AND meet the minds behind the work.
🔗

1
6
30
1
2
37
Looking forward to the 5th WNUT Workshop at
#EMNLP2019
on Noisy User-generated Text!
9:00-9:50am invited talk by
@IAugenstein
9:50-10:35am talks
11:00-12:15am talks
2:00-3:00pm one-minute madness (52 accepted papers)
3:00-5:00pm posters
5:00-5:45pm invited talk by Jing Jiang
1
7
35
ACL 2020 paper from
@SaifMMohammad
on the gender gap in NLP publications. A tribute to prior work by (
@natschluter
2018; Vogel&
@jurafsky
2012).
My main takeaway -- the figure below.
My question -- How much super highly cited papers swing the statistics?
#nlproc
3/n
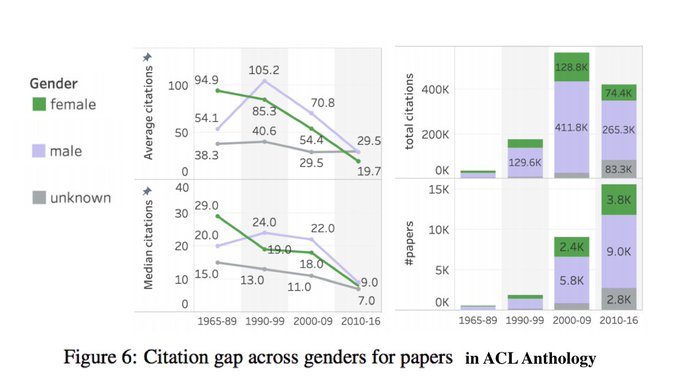
5
8
37
Great summary of doing a PhD. 😂😂😂
"Pro - Being surrounded by very intelligent and ambitious people. You’ll ... gain so many ideas from the people you meet.
Con - Being surrounded by very intelligent and ambitious people. It can get exhausting and frustrating after a while."

New blog post! ✍️
If you're applying to PhD programs, or thinking of applying in the future, here's my FAQ as a current grad student.
#AcademicChatter
TL;DR
- focus on advisors not schools
- get feedback, talk to everyone
- keep an open mind
2
54
277
1
0
37
It is nice that everything is back to life!
Enjoyed my first set of in-person visits and giving talks at
@cornell_tech
and
@columbianlp
on "Data/Controllability in NLG" and "Capturing Human Language Diversity & (Mis-)Information Spreading Online". Thanks to my super hosts.
0
0
36
Check out HashtagMaster -- split hashtags into meaningful word sequences (>90% accuracy).
It uses a pairwise neural ranking model designed by my student
@mmaddela1005
; demo by
@d_heineman
.
#MachineLearning
Paper:
Demo:
0
6
36
Looking for some human interactions at the virtual
#EMNLP2021
conference?
Workshop on Noisy User-generated Text (WNUT) will be live, with real-time Zoom talks & 70+ posters in GatherTown, two time zones (Nov 11 | 00:00-04:00 and 11:00-15:00 AST).

2
3
36
Preview of our NAACL 2018 poster "Character-based Neural Networks for Sentence Pair Modeling" 1st day of main conference (June 2) 15:30 - 17:00 (Semantics 1 Session)
#NAACL2018
@NAACLHLT
#nlproc

0
4
35
Time flies. Already 10% time gone for year 2021. 😱

2
1
35
New
#EMNLP2022
paper on generating very diverse and creative paraphrases by learning from real humans talking on Twitter!
Much more natural and realistic than existing work (e.g., back-translation; MSPC, QQP in GLUE benchmark). Work by my PhD students
@Yaooo01
@chaojiang06
.
Every day millions of people tweet about trends or news articles on Twitter, making it a great source to get diverse paraphrase data. We’re excited to introduce the Multi-Topic Paraphrases in Twitter (MultiPIT) corpora in our
#EMNLP2022
paper. 1/7
Paper:

1
6
39
0
1
35


Update from one NAACL Board member:
“not in favour of putting this (removing 1-month anonymity) to a vote. This is a major policy change and it needs careful consideration. Moreover, the ACL exec has put together a committee and we're working on this issue.”
I just sent a note to NAACL board to try to put removing anonymity deadline for NAACL conference into a vote.
Sorry, I should have done this sooner. But it requires two members (not only one) in order to put a motion into the vote … non-trivial task.
4
3
87
4
1
34
