Loubna Ben Allal
@LoubnaBenAllal1
Followers
3,873
Following
636
Media
79
Statuses
543
ML Engineer @huggingface 🤗 | @ENS_ParisSaclay - MVA
Paris, France
Joined September 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
México
• 1103890 Tweets
Morena
• 688685 Tweets
casillas
• 424456 Tweets
Xóchitl
• 340352 Tweets
Flamengo
• 334593 Tweets
The Loyal Pin is Coming
• 252553 Tweets
#ปิ่นภักดิ์Q51ใกล้เสร็จแล้ว
• 246065 Tweets
緊急地震速報
• 202109 Tweets
PREP
• 154885 Tweets
Stars
• 150627 Tweets
#CH3Apologize
• 92391 Tweets
Florencia
• 84858 Tweets
地震大丈夫
• 83868 Tweets
LEALTAD FURIOSA
• 70862 Tweets
Televisa
• 66233 Tweets
$GME
• 45054 Tweets
Mario Delgado
• 44323 Tweets
アラーム
• 29349 Tweets
Martha
• 28946 Tweets
Natalie
• 27869 Tweets
アラート
• 27572 Tweets
#HomeForHomeless
• 25591 Tweets
Borja
• 25528 Tweets
Stanley Cup
• 25159 Tweets
Panthers
• 24287 Tweets
Juliana
• 24254 Tweets
Bucaramanga
• 21083 Tweets
Homely Shelter
• 20691 Tweets
渡辺くん
• 17677 Tweets
Santa Fe
• 16456 Tweets
McDavid
• 14916 Tweets
Super Over
• 14290 Tweets
トロピカルツイスト・クワトロSサイズ
• 11477 Tweets
Tommie
• 10781 Tweets
kcon
• 10104 Tweets




















Pinned Tweet

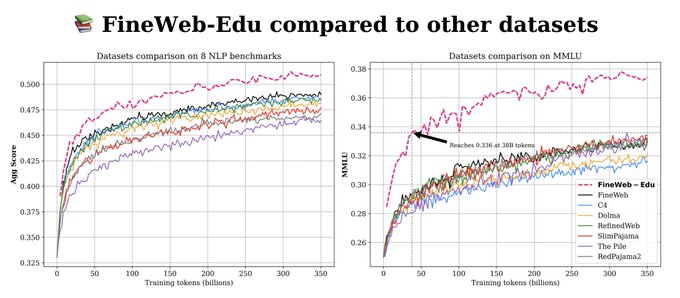
🍷 FineWeb technical report is out and so is 📚 FineWeb-Edu, a 1.3 trillion tokens dataset that outperforms all other open web datasets, with remarkable improvements on educational benchmarks such as MMLU, ARC, and OpenBookQA.
Technical report:
Dataset:
9
50
239
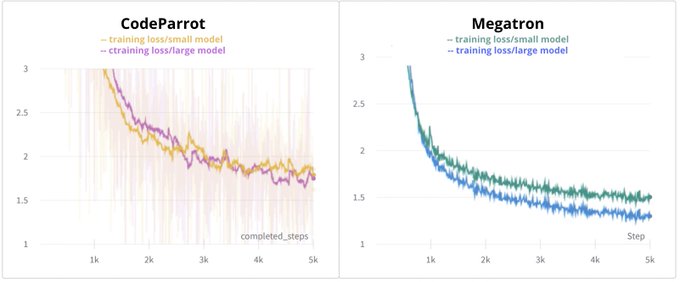
Debugging large scale pretraining is hard and expensive. We noticed that our CodeParrot training performed significantly worse than the equivalent Megatron training pipeline. Time for some investigation! 🕵️♀️ (1/n)
22
96
679
Last week we released StarCoder, a state-of-the-art code LLM with 15B parameters. With the release of StarCoder we also conducted a comprehensive evaluation of code LLMs.
Some interesting findings and how we got there ✨:
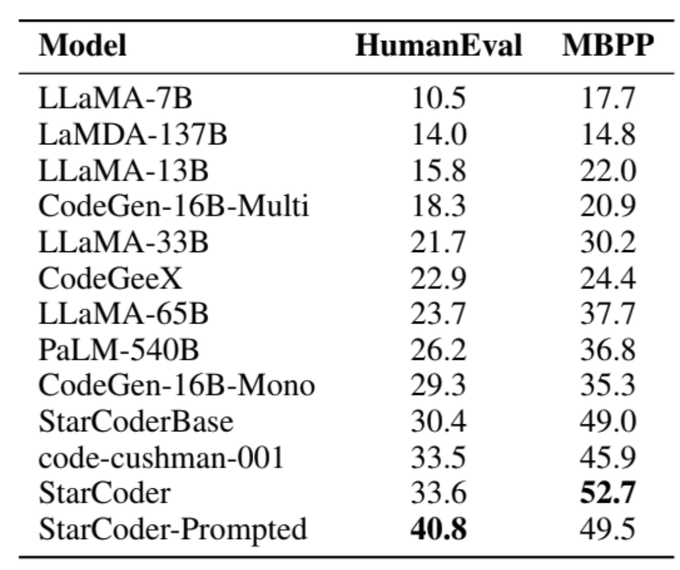
17
113
548
Today is my first day at
@huggingface
as a Machine Learning Research intern. I'm thrilled to be joining such an amazing team and contribute to democratizing the ML community 🤗
14
23
512
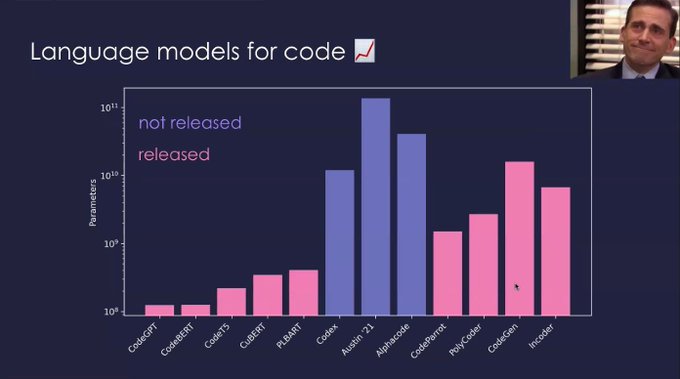
In the past two weeks, we've seen 4 new code models drop: StableCode, OctoCoder, OctoGeeX, and DeciCoder 🚀
Everyone's talking about "HumanEval" – so how does code evaluation work & what makes reproducibility challenging?
A thread 🧵:
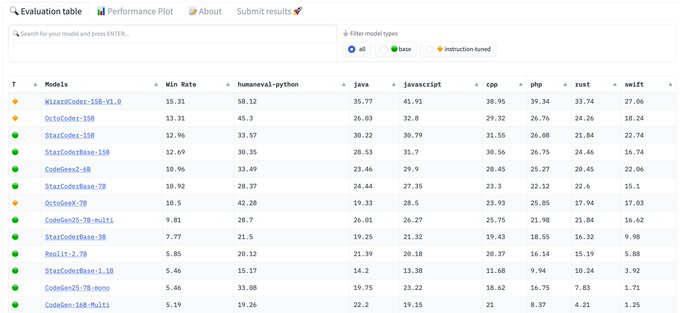
8
84
375
This is my second week as an intern at
@huggingface
. I am working on code models and as a first project I did some exploration of a large multilingual code dataset 💻. A thread:
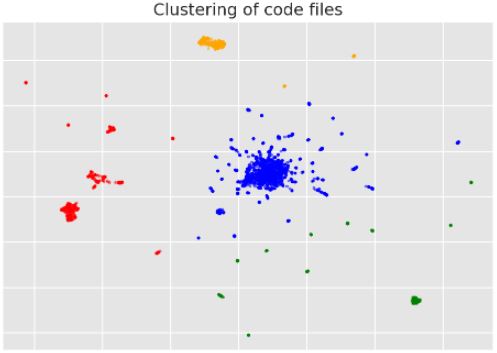
7
29
320
Since the introduction of Codex a lot has happened in the ML for code space with many large code models open-sourced. We built an interactive blog to compare all of these models and explain how they are trained and evaluated ✨:
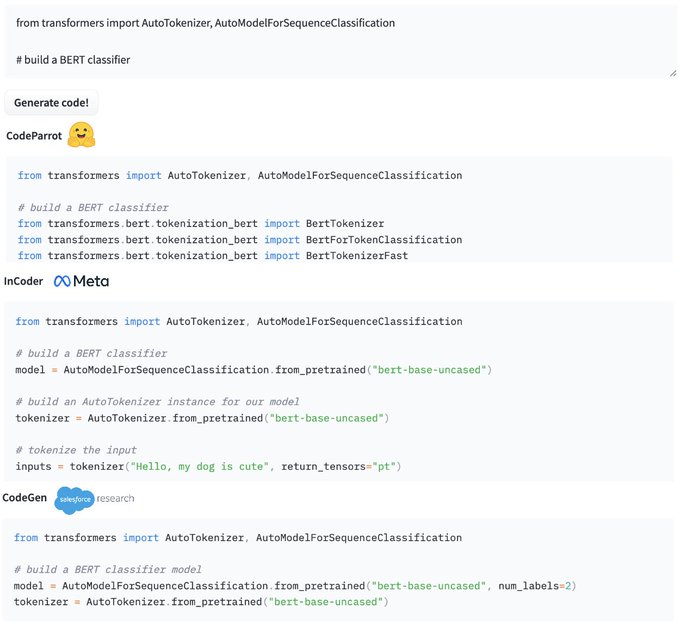
4
62
286
🌌 Cosmopedia: The largest open synthetic dataset of textbooks, blogposts and stories generated by Mixtral with a total of 25B tokens and 30M files 🚀
A little backstory to this "cosmic" journey: Two weeks ago I started experimenting with some cool web
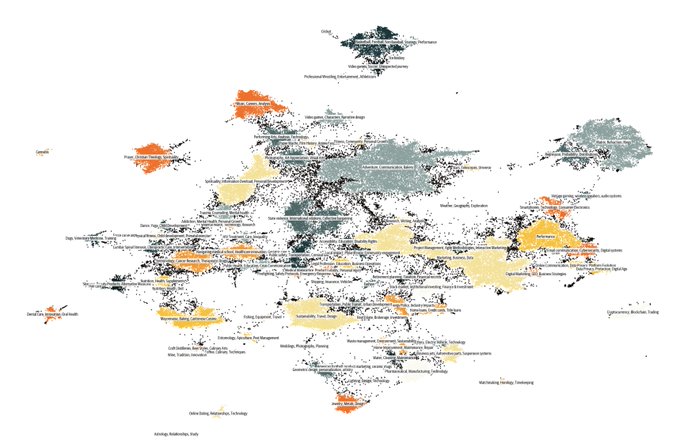
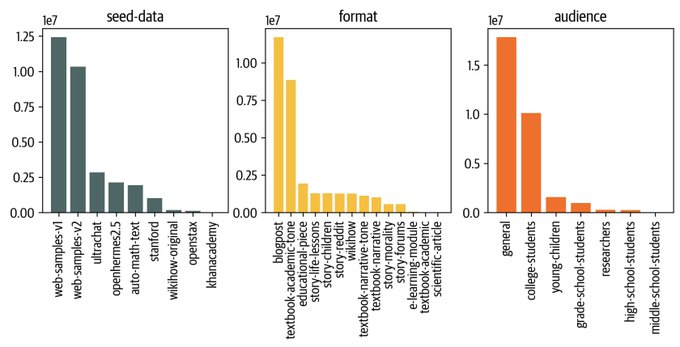
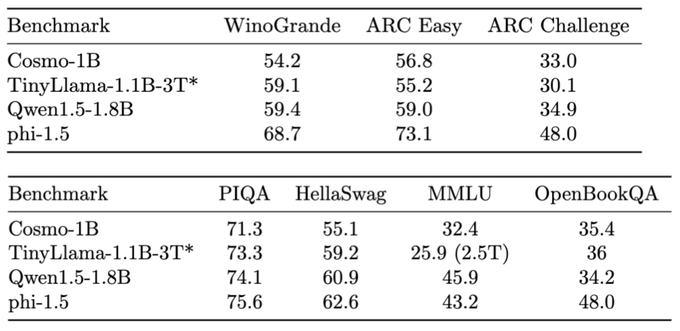
10
61
203
You probably heard of Megatron-LM for large model training, if you haven't tried it yet, we made this blog to guide you step by step.
You can train language models fast and convert them to 🤗 Transformers.

2
32
155
🧵 Here's how we're tackling text de-identification to remove personal information from code datasets at
@BigCodeProject
:
- An annotated benchmark 📑
- A pipeline for PII detection and anonymization 🚀
- A demo to visualize anonymized samples 🔍
(1/n)

2
36
143
Last week we released StarChatβ, an instruction tuned model of 💫StarCoder+.
In this thread, I will share some cool examples we generated with StarChat and show how it can be used to help you with coding questions.
A thread 🧵

4
35
130

Here's a Colab I shared internally at HF for running synthetic data generation at scale with llm-swarm
It’s very easy to use (once you have a slurm cluster 🙈) just provide your million prompts dataset, a model and let it run 🐝!
Would people be
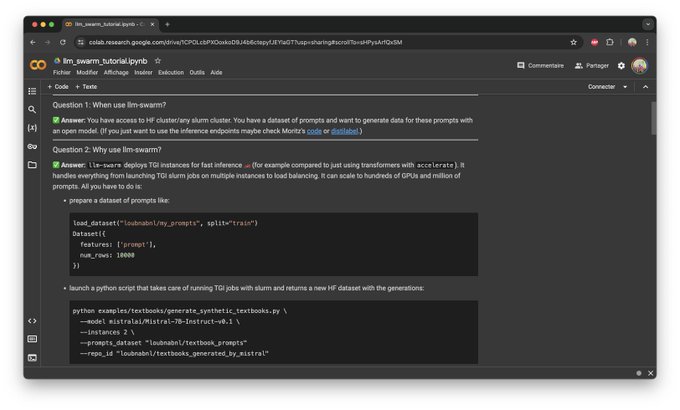
1
18
117
In BigCode, we want to train and open-source a large code generation model, but that’s not all. Here’s what makes this project different ✨: (1/n)
1
14
100
@nvidia
@DBahdanau
Debugging, although complex, is effective to fix small bugs even if they don't solve the initial problem ✨. It can be tricky for training scripts, as some changes require more time for their impact to be observed. We are now ready and training more models! stay tuned 🚀 (14/14)
8
3
84
🚀 Fine-tune SantaCoder on code generation datasets with this repo:
A Google Colab by
@mrm8488
is also available.
✨ Bonus: we fine-tuned SantaCoder on Jupyter Notebooks to make it explain code
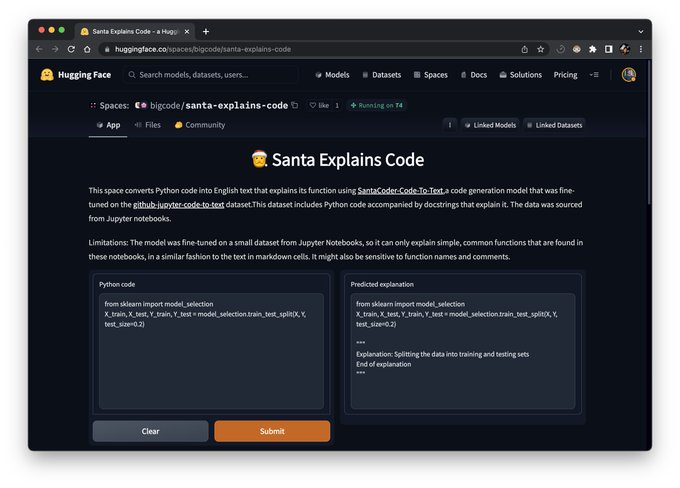
2
15
78
Here's the full list of the resources and links:
- Cosmopedia dataset:
- Cosmo-1B model:
- GitHub code:
⚡ Other libraries we used:
- llm-swarm for large scale synthetic data generation:

🌌 Cosmopedia: The largest open synthetic dataset of textbooks, blogposts and stories generated by Mixtral with a total of 25B tokens and 30M files 🚀
A little backstory to this "cosmic" journey: Two weeks ago I started experimenting with some cool web
10
61
203
1
13
72
The much-debated Phind and WizardCoder Models have joined the BigCode Leaderboard, evaluated across 10+ languages! 🌍
It took some time to get the correct evaluation results due to some evaluation subtleties. Dive into our exploration🕵️♂️🧵:
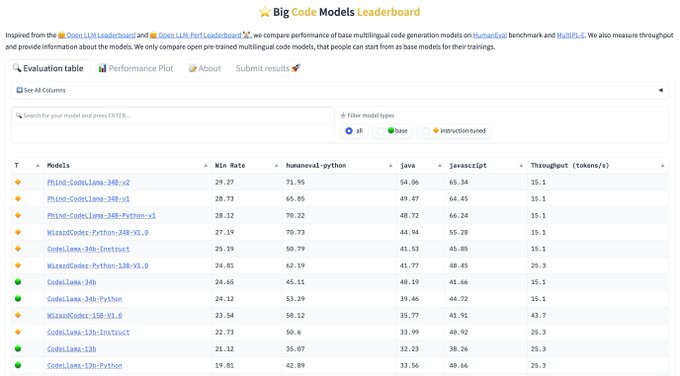
3
15
72
With many great resources for code models scattered around, it is hard to keep track. We’ve added several code-related datasets, models and metrics to the 🤗 hub for downstream tasks. Want to learn how to train models to estimate algorithmic complexity or explain code? A thread:
2
12
71
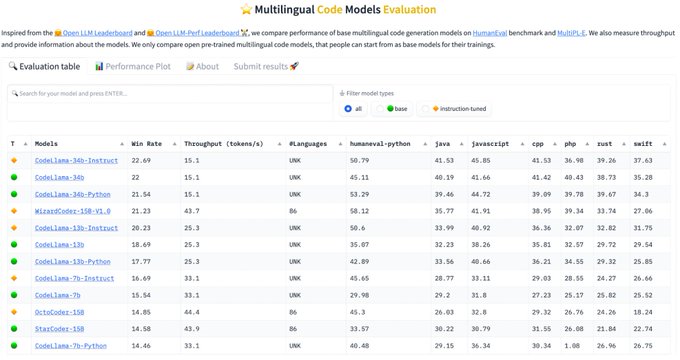
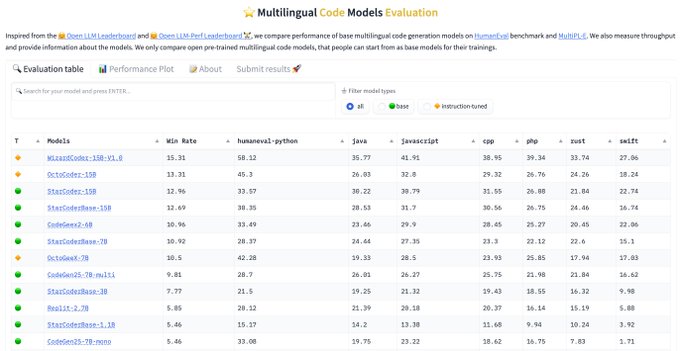
Inspired by the Open LLM LeaderBoard, and with several strong code models released, we created a Multilingual Code Leaderboard:
📊 10+ programming languages
⚡Throughput measurement
🔬 Fully reproducible
✉️ Open for submission of results
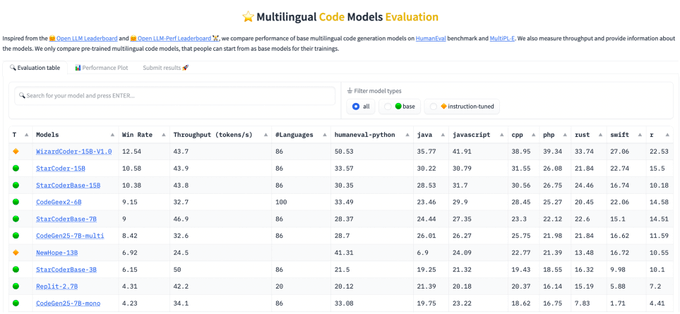
2
10
68
The new CodeQwen1.5-7B models rank very high on the BigCode Leaderboard, outperforming much larger models🚀
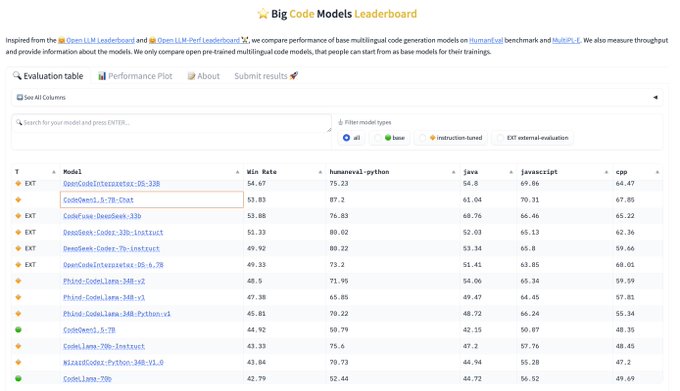

🔥 Do you want an open and versatile code assistant? Today, we are delighted to introduce CodeQwen1.5-7B and CodeQwen1.5-7B-Chat, are specialized codeLLMs built upon the Qwen1.5 language model!
🔋 CodeQwen1.5 has been pretrained with 3T tokens of code-related data and exhibits
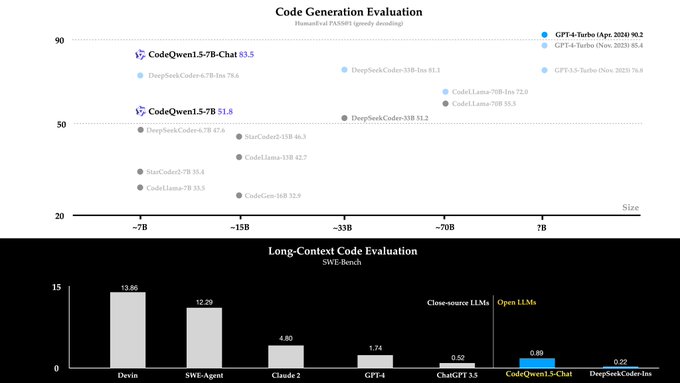
26
123
605
1
9
62
We are releasing all the tools we developed under open-access, and we hope they will advance the code generation space. Releasing a model is not just releasing a checkpoint ✨
You can find all relevant links at:
Paper:
5
5
58
@nvidia
@DBahdanau
🥁 And indeed when training with all these fixes a bit longer we noticed that the discrepancy was gone and we now match Megatron's performance 🥳! (13/n)
2
2
56
We've just published a detailed blog post on the creation of Cosmopedia dataset. We hope this will provide insights about generating synthetic data at scale for pre-training.
Here are some key takeaways:
🎯 Prompt curation is crucial: we want to cover

1
10
54
@nvidia
@DBahdanau
Next we tried the data loader from Megatron. Initially we had a shuffling problem (credits to
@DBahdanau
), the files were shuffled but not the sequences, so those from long files can fill up a single batch. This improved the training considerably but wasn’t enough. (7/n)
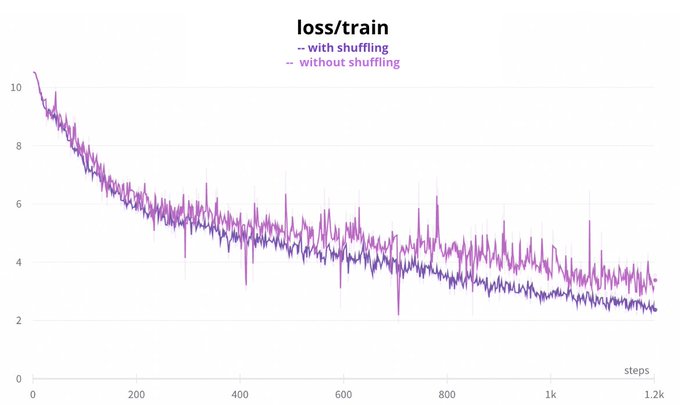
2
1
49
When testing the model, we were struck by its conversational and reasoning abilities when we added a series of dialogues to the context: It can act as a tech assistant. Evaluation on HELM reasoning tasks:
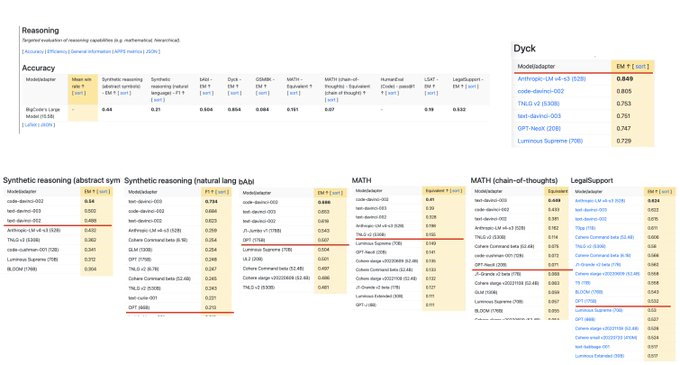
1
5
43

@nvidia
@DBahdanau
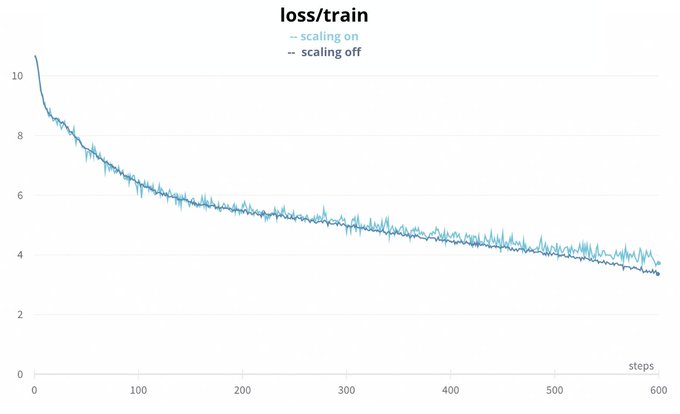
At this stage, we thought we might’ve missed something in the points above. We found there was a difference between the frameworks in the scaling of the attention weights in mixed precision. We fixed the difference and finally got a slight improvement! (9/n)
2
1
41
Based on popular demand, we trained smaller versions of 💫 StarCoder.
Check this leaderboard for more details on their performance compared to other base code models:

🌌 News from the StarCoder cosmos!
We trained smaller versions of StarCoder: 1B, 3B and 7B models.
1T tokens, 80+ programming languages with 8k context window, MQA & FIM.

3
74
251
2
9
40
Last week, I gave a keynote about
@BigCodeProject
and
@huggingface
ecosystem to 1500 attendants at the
@KubeCon_
&
@CloudNativeFdn
summit and GOSIM conference in Shanghai. It was a great chance to meet the Open Source community and discuss AI!
Slides:


6
3
40
Another cool feature for Gradio. We used these API endpoints in our Code Generation blog to call 3 other spaces in parallel threads without needing to load many large models in one space.
Code Generation Blog:
CodeGen space:

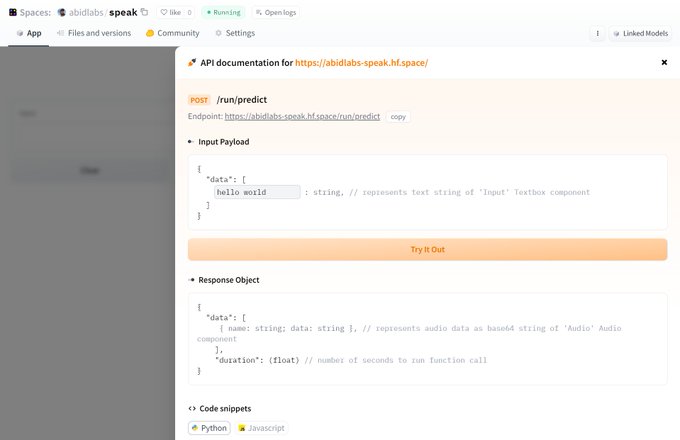
Really stoked to share Gradio's new "Use via API" page
1⃣ Build a
@Gradio
app (or find one on Spaces)
2⃣ Click on the "Use via API" link in the footer
3⃣ See the expected payload and try it out immediately
4⃣ View handy code snippets in Python or JS
Embed ML everywhere!
5
24
154
0
7
39
We're live with StarCoder2!
Introducing: StarCoder2 and The Stack v2 ⭐️
StarCoder2 is trained with a 16k token context and repo-level information for 4T+ tokens. All built on The Stack v2 - the largest code dataset with 900B+ tokens.
All code, data and models are fully open!

14
193
681
0
6
36
Another architectural change which feels like a must for every new language model is Multi-Query-Attention, you can process larger batches and faster!
If you ever evaluated a code model you must know how necessary that is

A very underrated architecture tweak to GPT is multi-query attention (MQA): sharing value/key across attention heads saves a lot of memory in the kv-cache.
Max generation batch size on a Colab GPU with a 1B model:❗️512❗️ vs 32 (vanilla GPT)
Test it here:
7
72
341
2
2
35
@nvidia
@DBahdanau
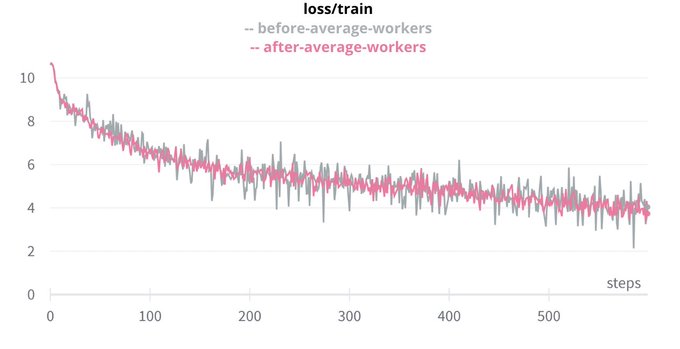
First, we observed that our loss had more noise than Megatron’s. We used distributed training and we were plotting the training loss of the main worker only, plotting the average over the workers made the loss way smoother! (3/n)
1
0
35
@nvidia
@DBahdanau
Then we thought maybe the optimizer is the issue: the transformers implementation of AdamW is slightly different from Pytorch and will be deprecated. Switching to AdamW from Pytorch exhibits better behavior after the warmup stage but then the performance becomes similar. (11/n)
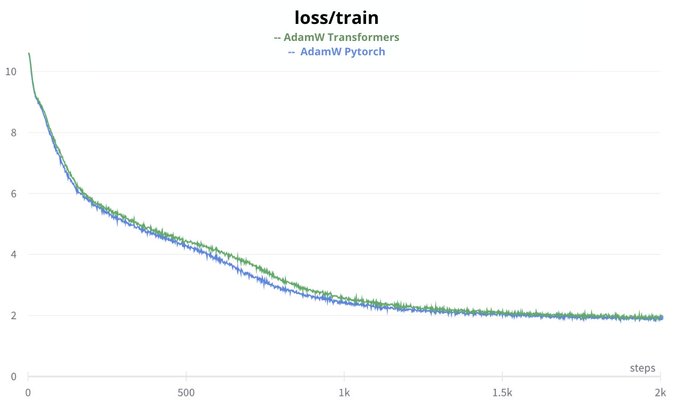
1
0
34
@nvidia
@DBahdanau
The only thing left to check was the rest of the training script. We found a bug in the weight decay! However it didn’t seem to impact the training on the short run. We also used 🤗 Trainer to replace our training loop in case there was another bug, but there wasn’t. (8/n)
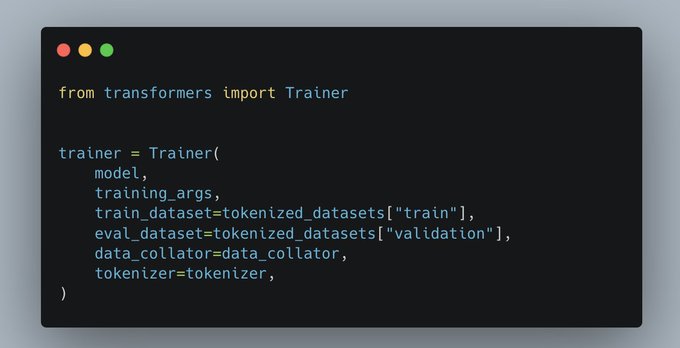
2
1
33
@Grady_Booch
We also do have a lot of incorrect, wrong & inappropriate information on the web, that is used to train today's LLMs. At least with synthetic data you can have some control over what you generate. Hallucination remains an issue for sure, there are methods to attenuate it like
3
0
33
Glad yo see Cosmopedia as the top trending dataset on the HF hub since we released it 3 days ago 🚀
Cosmo-1b model:
This is our attempt at reproducing the dataset used to train Phi models but with an Open Source model. It’s a
1
3
34
@nvidia
@DBahdanau
Naturally we compared the architectures of GPT2 in both frameworks to look for any differences. The only difference we found was in the GELU activation function, they use slightly different implementations, but this didn’t impact the training. (5/n)
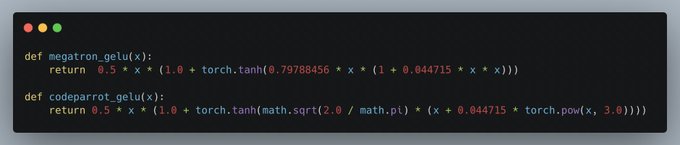
1
0
32
A LOT of data curation.🕵️♀️ We manually inspected 50-100 files for all the extensions in the selected programming languages and choose adequate filters.
We also added GitHub Issues, Git Commits and Jupyter Notebooks.
Overview of some of the spaces we built:

2
2
33
@nvidia
@DBahdanau
But we got excited too early, after some discussions with the authors of this change they explained that it doesn't impact the training in the long run. And indeed, going beyond 2000 steps makes the gap go away. (10/n)
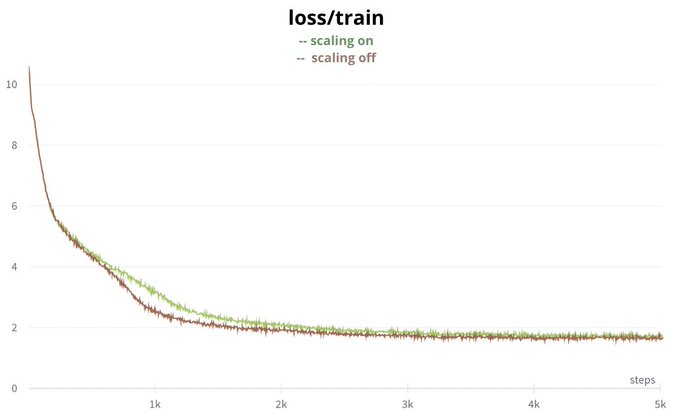
1
1
32
Megatron is a framework developed by
@Nvidia
for training large transformer models.
@DBahdanau
observed a training gap for CodeParrot, a GPT2 model for code generation, between Megatron and our script in transformers. (2/n)
2
0
32
@nvidia
@DBahdanau
Another candidate for the difference was the optimizer, we used AdamW from transformers, while in Megatron they used AdamW from Apex. We trained the model with the latter but it didn’t seem to solve the problem 😓 (6/n)
1
0
32
@nvidia
@DBahdanau
Then we suspected that the initialization weights could be different between the two frameworks, but it turned out they followed the same distributions. (4/n)
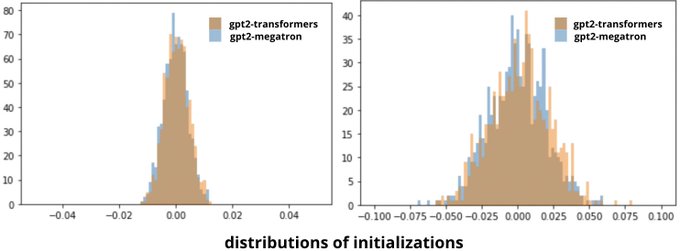
1
1
31

⚖️ StarCoder is not just a strong model- it sets a new standard for data governance. We trained only on permissive data with an opt-out mechanism and no PII.
We also implemented tools for code attribution like a membership test: and a search index.
1
4
30
Here's a nice tool for visualizing and clustering your dataset into topics 🔍
We used it to understand topic coverage and filter web samples when building Cosmopedia:

Text clustering at home? Yes, with text-clustering, a tiny smol repo:
The pipeline is fully built on open tools:
1⃣embed with sentence-transformers
2⃣project to 2d with UMAP
3⃣run DBSCAN clustering
4⃣label clusters with Mixtral
Runs in 5-10min and tada:
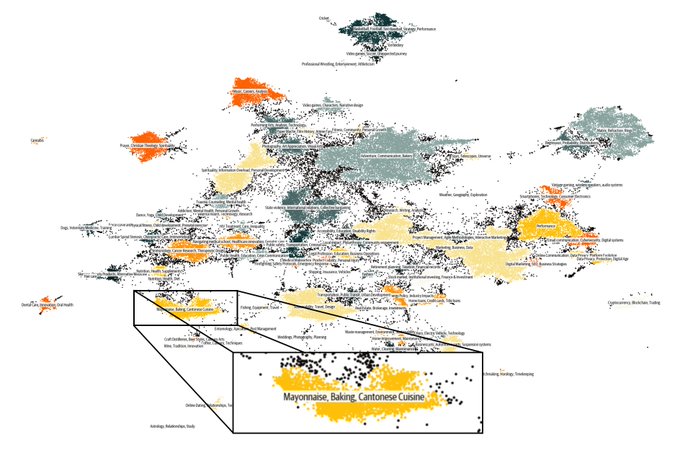
10
45
285
1
1
28
If you contributed code to GitHub and permissively licensed it, you might help build the next generation of code language models 🚀
Is your code in 📑 The Stack? Check if your repositories are in the dataset and a large language models for code will learn from them!
You don't want your code to be part of The Stack? Follow the opt-out instruction and we'll remove it!
4
24
65
0
4
29
We trained for multiple epochs without performance degradation. The scaling laws indicate that a 15B model trained on the 300B tokens we had would be very undertrained.
=> We repeat data until the magical 1T tokens ✨
The loss kept going down!
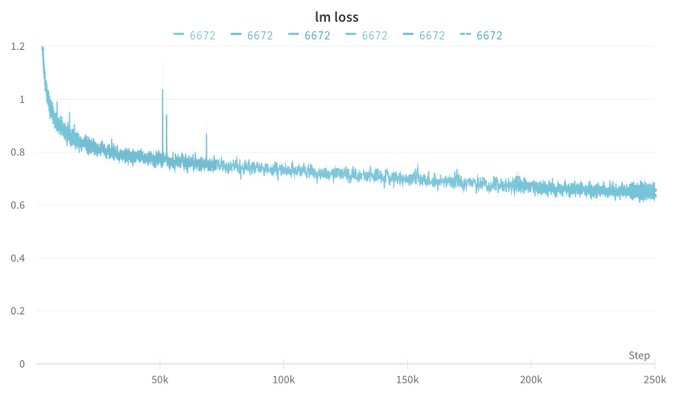
1
1
29
Code generation with language models is cool. Complexity prediction is even cooler!
This Gradio space predicts the complexity of Java programs using a code model ⏱️ :
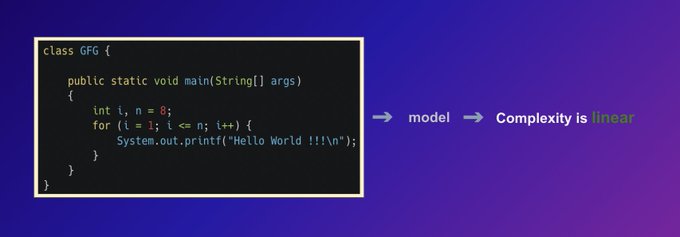
1
7
27
Join us tomorrow to learn more about StarCoder 💫

Can't wait to hear about StarCoder from
@LoubnaBenAllal1
! ICYMI, StarCoder is a code LLM from Hugging Face with 15B params & 8k context, trained on 1T tokens of permissive data in 80+ programming languages.
Starts in 24 hrs: May 16, 9am PST. RSVP below.
2
6
27
0
4
26
🇲🇦 Proud to see this platform we developed with fellow Moroccans help in earthquake relief efforts. To contribute please visit:
We have a map for coordination + forms and a WhatsApp bot for victims, witnesses & NGOs:


Our very own
@Nouamanetazi
was on Moroccan national television
@2MInteractive
to talk about the
@huggingface
Space he and
@LoubnaBenAllal1
created to aid in
#MoroccoEarthquake
relief efforts🙏
Link to Space:
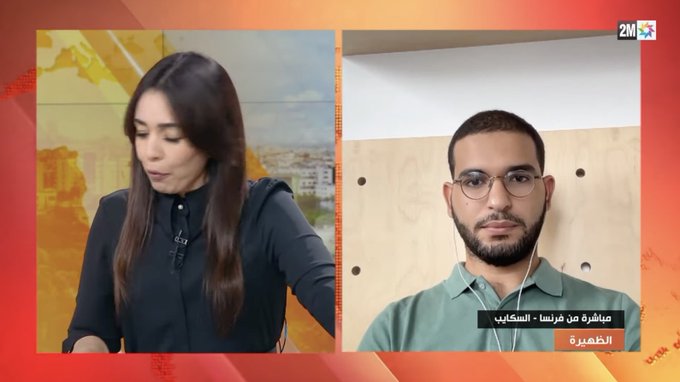
1
4
31
0
5
27
@nvidia
@DBahdanau
We were quite desperate already but we hoped some of these changes would exhibit a difference in a longer training 🤞 (12/n)
1
0
26

2
7
26
Architecture-wise, we used FlashAttention to increase our context window to 8k 🚀
This can help when large context is needed for example to support repository-level information in IDE integrations.
2
1
25
StarCoder outperforms OpenAI's code-cushman-001 and all open code generation models on HumanEval. On other benchmarks like DS-1000 the gap is even larger.
DS-1000 includes more diverse and realistic data science problems spanning 7 libraries.
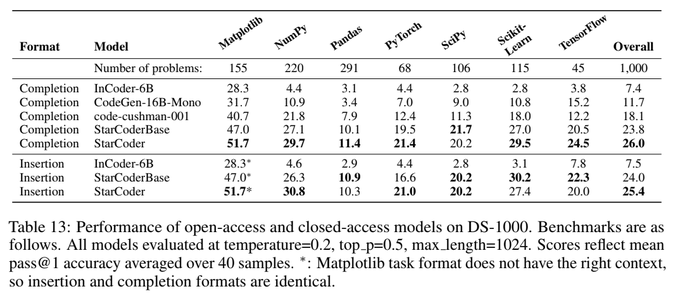
2
4
24
StarCoder and StarCoderBase are trained on 86 programming language and are very good at many:
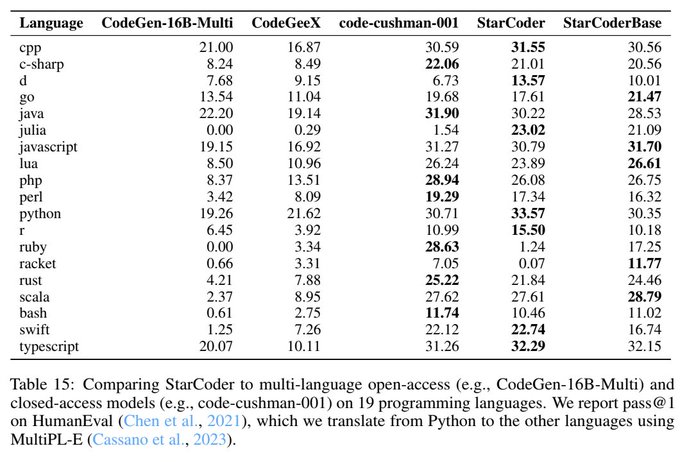
1
1
24
You can reproduce most of these numbers, with our code evaluation harness:
It Includes MultiPL-E (HumanEval in 18 languages), HumanEval, DS-1000, PaL-GSM8k among others with Multi-GPU setup & docker containers for execution.

1
2
23
Check our blog for details on the new Code LLaMa family:
We also updated the Code Leaderboard to integrate all 9 models:

Code Llama with
@huggingface
🤗 Yesterday,
@MetaAI
released Code Llama, a family of open-access code LLMs!
Today, we release the integration in the Hugging Face ecosystem🔥
Models:
👉
blog post:
👉
Blog post covers how to use it!
7
80
297
1
2
23
Next Tuesday, I will give a webinar hosted by
@AnalyticsVidhya
on the training of LLMs for code, like StarCoder.
I will also discuss how to leverage these models using open-source libraries such as transformers, datasets and PEFT.
Register here: .

1
3
23
Honored to have given a talk at
@KTHuniversity
about Machine Learning for Code at
@Huggingface
with CodeParrot & BigCode.
🦜 For educational tools about code models:
🌸 For some state-of-the-art code datasets and models:

1
6
23
Happy to be speaking at
@llm4code
workshop!

Very excited to share the 1st
@llm4code
workshop has attracted 170+ registrations!
If you’re at
@ICSEconf
and interested in LLMs, pls join us on April 20, we have 24 presentations and two keynotes on Code Llama (
@b_roziere
) and StarCoder2 (
@LoubnaBenAllal1
)!
#icse24
#llm4code
1
5
44
2
2
20
@linoy_tsaban
and I already got our 🎃 Halloween photo at: try it out!


Introducing 🎃🦇 the AI Halloween Photobooth! 🦇🎃
Turn into a Spooky Skeleton💀✨ or a PS1 style vampire 🎮🧛
From
@linoy_tsaban
and I, powered by LEDITS 🎨: spooky iteration of what we had
@ICCVConference
/
@huggingface
Paris event🕸️🕷
Go play! ▶️
4
14
61
0
5
19
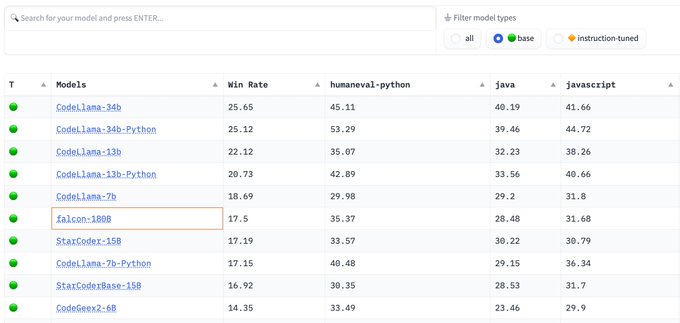
@Thom_Wolf
@radAILabs
@Dr_Almazrouei
@TIIuae
@huggingface
It has 35.37% pass
@1
on HumanEval. You can also compare it to code models on 10+ programming languages in the Big Code Models Leaderboard:
2
4
16
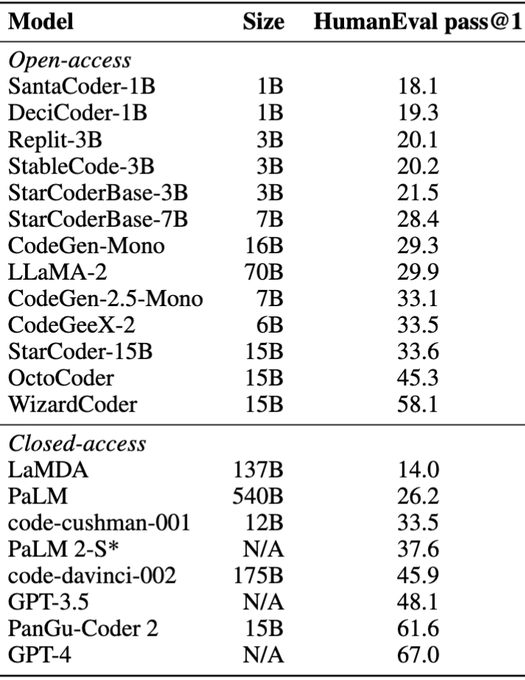
Happy to see our models and datasets getting adopted by the community 🚀
The power of building tools, datasets, and models in the open: the community can build on top of it and everyone profits!
Exhibit A: since the release of 📑The Stack and ⭐️StarCoder research groups from academia and industry have trained models on top BigCode's releases.
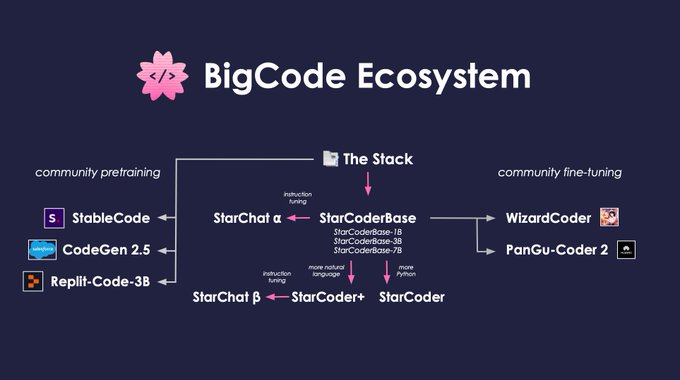
2
26
88
1
1
18
Thank you for the invitation, it was a pleasure to give this webinar 🤗

Thrilled to announce the success of our recent
#webinar
on Generative Models with Loubna Ben Allal.
If you missed it, watch the recording here:
Take our survey to improve future events, & stay tuned for more!
#MoroccoAI
#AI
#NLP
0
3
18
1
1
18
Happy to see The Stack released 🚀
For more information about the dataset and models we trained checkout this paper
Introducing 📑 The Stack - a 3TB dataset of permissively licensed code in 30 programming languages.
You want your code excluded from the model training? There is an opt-out form and data governance plan:
Let's take a tour🧵

15
232
1K
1
2
17
For more details about the dataset or how to train a large language model on code from scratch, please visit the following links 🤗:

1
0
17


DS-1000 is a realistic Python benchmark of Data Science use cases based on Stack-Overflow questions. It consists of 1000 problems spanning 7 widely-used libraries, and it was developed by
@HKUniversity
NLP Group.

1
3
16
You play more with the model at StarChat Playground:
Or you can deploy your own Chat-UI:

0
1
16
Check our latest StarCoder descendants: StarCoder+ and StarChat Beta, a strong chat assistant with high coding capabilities 🚀
📣 Introducing ⭐ StarCoder+ & StarChat Beta!
We trained StarCoder on the Falcon model's English web dataset and Instruction-tuned it. Both models rank high in the LLM leaderboard, with strong natural language performance and coding capabilities.

8
105
383
1
3
15
📊 So if you're looking for a reproducible & central place for the evaluation of code models, check our multilingual code leaderboard:
1
3
14
📈 Significant progress was made in the code evaluation space, but there's more to tackle such as:
• Evaluating repo level & multi-file changes
• Testing for class implementations
• Improving test coverage
2
1
14
MultiPL-E is the translation of HumanEval to 18 programming languages by
@northeasterm
Programming Research Lab.
It powers the Multilingual Code Evaluation leaderboard

1
2
14
In BigCode we developed a code evaluation harness to facilitate this task:
@MosaicML
is developing an end-to-end solution for code evaluation:
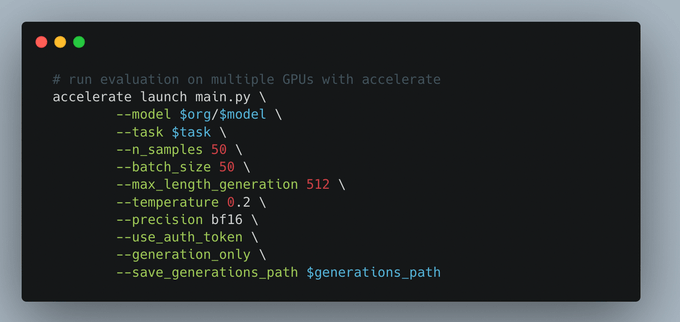
1
2
13
@d_aumiller
Indeed it can be expensive which is why we trained for a few steps to test the changes (but this can also lead to false conclusions). I think it’s important to split the problem in small pieces and keep track of everything that was tested an the order of the tests
0
0
13
Join us on the BigCode journey 🚀 and contribute to the next language model for code.
Together we will address the challenges of this field in an open and responsible way 🌸.
print("Hello world! 🎉")
Excited to announce the BigCode project led by
@ServiceNowRSRCH
and
@huggingface
! In the spirit of BigScience we aim to develop large language models for code in an open and responsible way.
Join here:
A thread with our goals🧵

5
74
215
1
1
13
In NLP, model generations are often compared to reference solutions using metrics like BLEU 📜↔️🔍
But for code, these metrics don't capture the large and complex space of possible solutions.

1
1
13
Let's go back to HumanEval: It's less than 200 problems, with only function implementations in Python. Is that all you expect a code model to do? 🤔
The answer is no, which is why researchers have developed other benchmarks such as DS-1000, MultiPL-E, APPS...
1
2
12
@Jakewk
It's textbooks generated by an LLM, there's some hallucination for sure, but the performance of the model we trained on the dataset suggests there's a large chunk is accurate. You can inspect some samples here:
3
1
12
🚀 Latest feature on HF hub: You can now follow people!

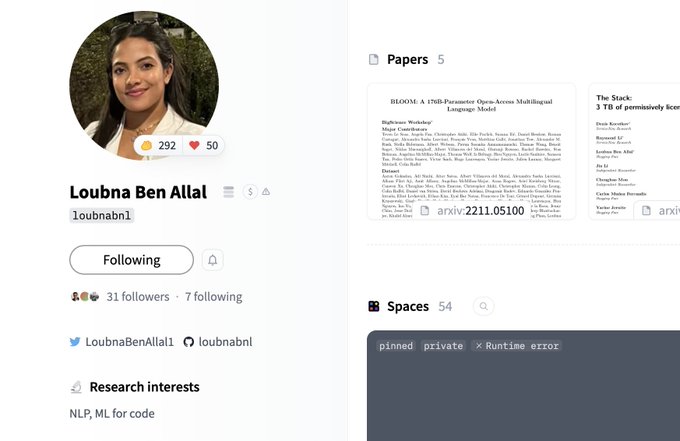
0
0
11
We built this demo this using 🤗 Spaces, an easy tool to deploy free apps, more than 14B parameters are hosted in this single space. If you have any questions or feedback you can use our new 🤗 feature of the hub: community tab, or even open a PR!
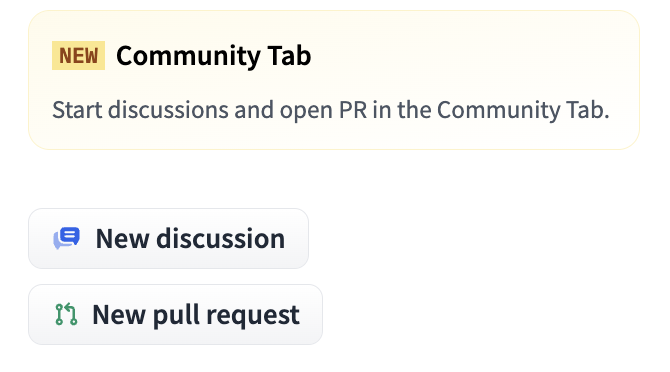
0
0
10
These examples were generated by deploying a local version of the amazing Hugging Face Chat-UI:
🔍 If you want to dive in the TS source code of how the prompt is built, StarChat can help!

1
1
11
Last, we included a demo where you can prompt the models and generate code! Give it a try!
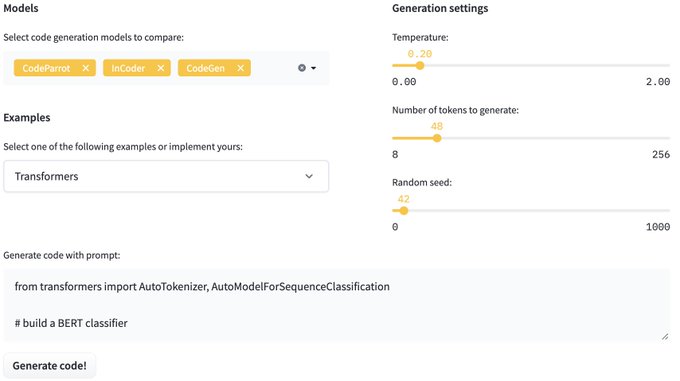
1
1
10
Although HumanEval appears to be correlated with performance on other code completion benchmarks, it may not effectively capture model nuances in various scenarios.
Therefore, it's necessary to evaluate code models across multiple tasks. From StarCoder's Model Card:
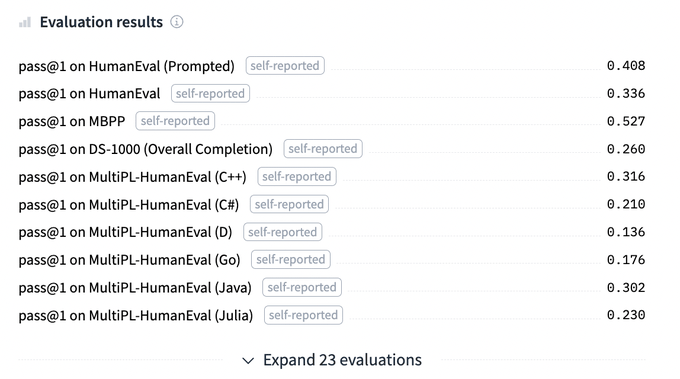
1
2
11
That's where functional correctness shines, we test model generations against unit tests, like humans would. And we report a score called pass
@k
.
➡️ HumanEval = 164 Python programs with 7.7 tests per problem in average.
1
1
11
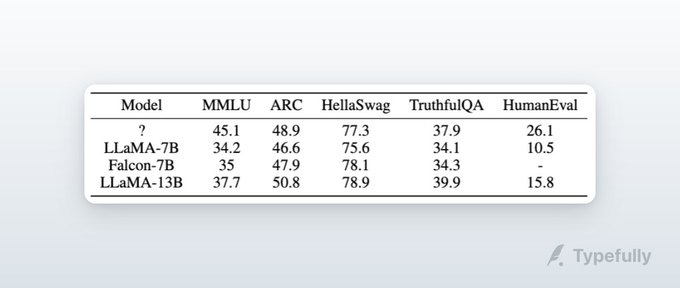
The instruction-tuned version of StarCoder2 is out by the HuggingFaceH4 team 🚀

We've applied a variant of the Zephyr recipe to create StarChat2 🌟!
It balances the code and math capabilities of BigCode's StarCoder2 with those of chat models to produce a capable programming assistant 👩💻
🚀 Demo:
🧑🍳 Recipe:
3
22
90
0
1
9
@GrantDeLozier
@Thom_Wolf
It was actually a bug in the weight decay not LR, because of a typo it was also applied to LayerNorms that are normally excluded. And yes we do plot the learning rate curves it’s good practice to follow how it changes
1
1
9
We now host APPS (Hendrycks et al), a popular benchmark for evaluating code generation models with 10000 problems of three difficulty levels. We added the dataset as well as the metric.
Dataset:
Metric:
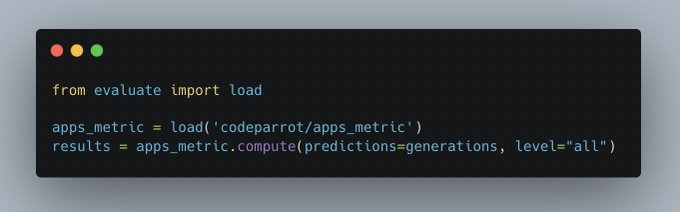
2
2
10
Each HumanEval prompt is a function signature with a docstring.
Instruction-tuned models are more chatty (GPT3 vs ChatGPT). They can either be evaluated with this prompt, or with an instruction friendly format to better align with their fine-tuning.
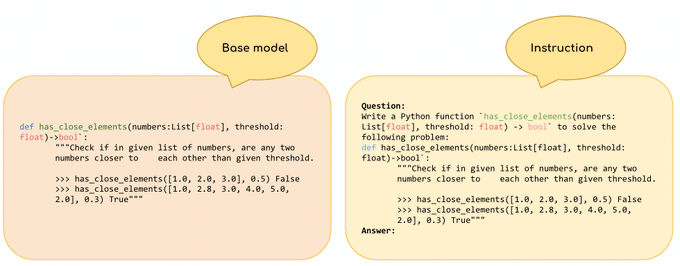
1
1
10
Check starcoder.cpp by
@Nouamanetazi
to run StarCoder at lightning-fast speed! ⚡


The first code model has officially joined the ggml library 🚀 VSCode extensions / On-device code generation.. The possibilities are endless. Let's level up the coding game with the power of ggml!
👉
1
14
56
1
2
9
Stay tuned ✨!
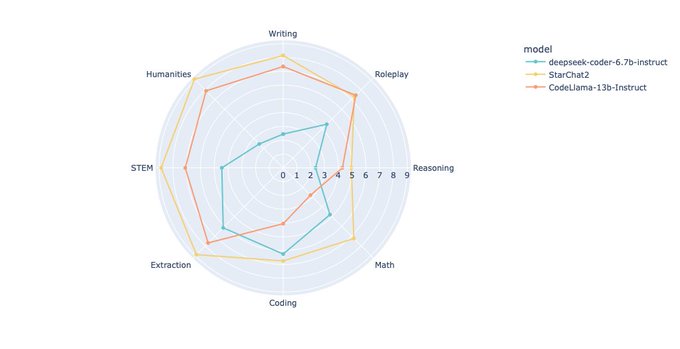
👀 A glimpse of our latest mystery model's performance. Not just acing the coding tasks, but also mastering natural language! Intrigued yet?
Join us at our StarCoder webinar this Thursday to find out:
1
21
108
1
1
10
@thukeg
Great work! We added HumanEval-X to the Hugging Face hub and we can transfer it to your HF organization . It would be great to have the models there too!

3
1
10
🔍 Reproducibility is a also big challenge due to variance in:
• Generation parameters (n_samples, temperature...)
• Evaluation sets (HumanEval vs MultiPL-E-Python)
• Prompts (prefixes, base vs instruction)
➡️A leaderboard is essential for clarity in this space.
1
1
9
You can find more information in CodeParrot organization including preprocessed large code datasets used in our experiments ✨

1
0
9
There are also other benchmarks for testing tasks like Program Repair and Code Explanation within HumanEvalPack thanks to
@Muennighoff
& team's work in
@BigCodeProject
.
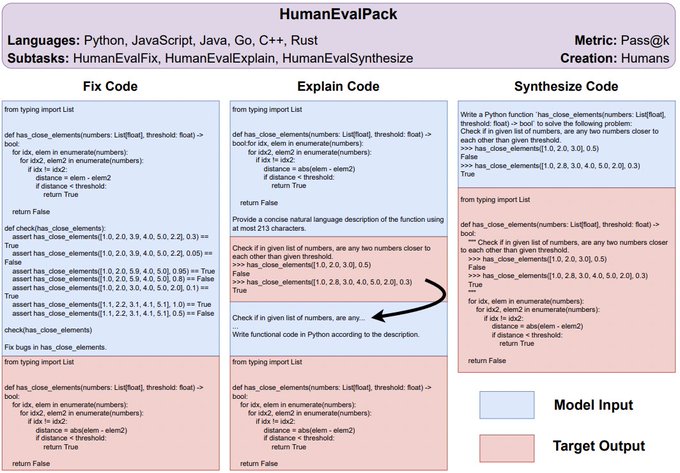
1
3
9
StarChat Beta might hallucinate and generate problematic output. After all it's still a Beta version, but it shows we’re on a good path for code models that are open-access but also strong ✨
1
0
9
🔍 So what's the secret sauce for StarCoder's performance?
2
0
9